|
I was very busy lately and did not the news until the Twitter tag #BlokirKominfo was trending. Not just surprised, but I was shocked to find Steam, a platform where I bought over $1000 of games was blocked. After reading more news, I found out that PayPal was also blocked. This received massive online protest because many Indonesians are freelancers and received their salaries in PayPal. Therefore blocking PayPal, is the same as cutting of their income where if that is their only source of income, then they are threatened to be starved on the street. If that was not shocking enough, Yahoo was also blocked.
Authority ResponsibleThe Authority that governs Internet access is The Ministry of Information and Communication Indonesia. The reason is because the law that requires all online service providers to register as electronic system operator. The reason is to make sure Indonesian user data are protected and the online service does not violate Indonesian's Law. However, here is the catch that maybe true or false: online service providers are required to share Indonesian user data to the government. I learned that there are 2 main phases:
My Campaign Against Censorship
It all started when pornographic contents went viral among underage childrens. The government passed a law that any type of pornography is illegal. Then finally the authority started banning pornography websites and other contents. It was fine until this point, but I got annoyed when they started banning animations, anime, comics, manga, and other arts. Still this was tolerable and I only kept to myself my knowledge of bypassing this censorships. 
After that, they went too far. They started to ban Reddit just because there are pornography sections there, eventhough most of the contents are knowledgeable discussions. Although a decade have passed, they still blocked the whole website and not bother releasing partially of safe contents. Even when I needed additional information about DeFi portfolio trackers, I cannot obtain them because I cannot access its Reddit discussion. This is the start of campaign against censorship. 
It gotten worse by targeting trading platforms such as Bybit and Bityard and even crypto platforms such as Binance. A very useful application that we can earn income by performing simple tasks such as participating in surveys and testing apps Cointiply may not be blocked but was removed from Indonesian mobile store. Today, citizens are finally protesting because these websites are blocked: What Can Regular Citizens Do?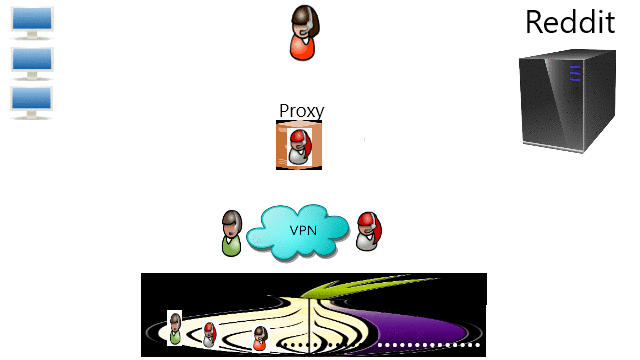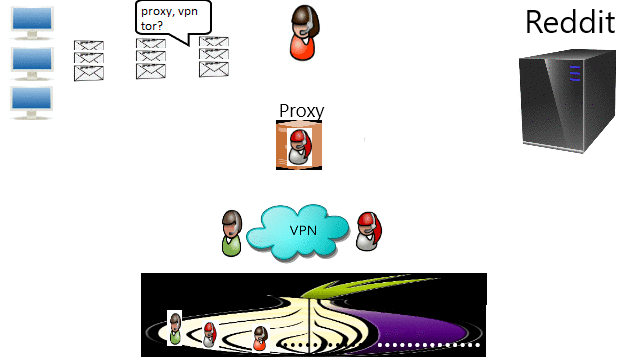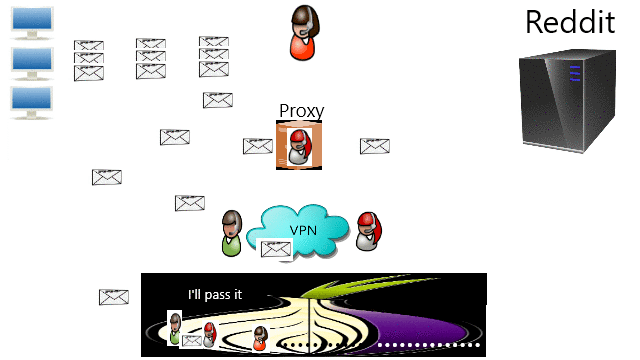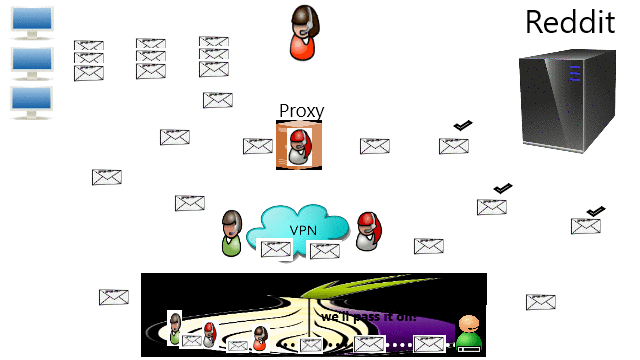
It was for this moment that I wrote a tutorial about Common Ways To Bypass Internet Censorship. The first method to try is by DNS because that is the simplest one with least performance issue. If that does not work than the second method is either through Proxy or VPN. The third method is through TOR if privacy is wanted. Providers should really consider migrating to decentralization such as blockchain technology and IPFS. Finally, the root problem is the tyranny that we should stand up to the authority.
0 Comments

Payments & Donations & Other Wealth Transfer in Cryptocurrency
Expert Transaction Monitoring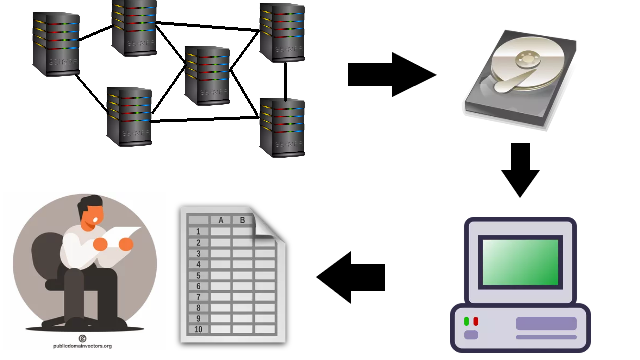
3rd Blockchain Explorer Providers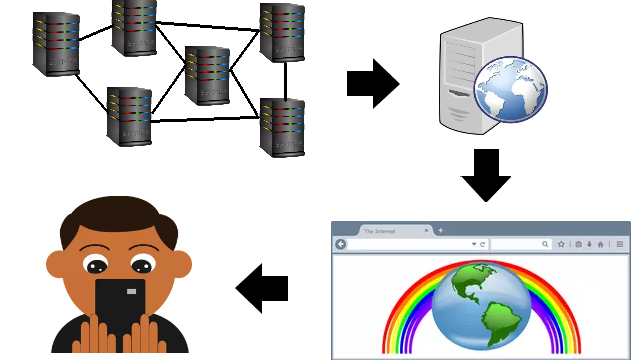
Virtual Machine Compatible and Forks
Bitcoin ForksThere are many Bitcoin forks based on https://forkdrop.io/how-many-bitcoin-forks-are-there but I will only list those that donated. 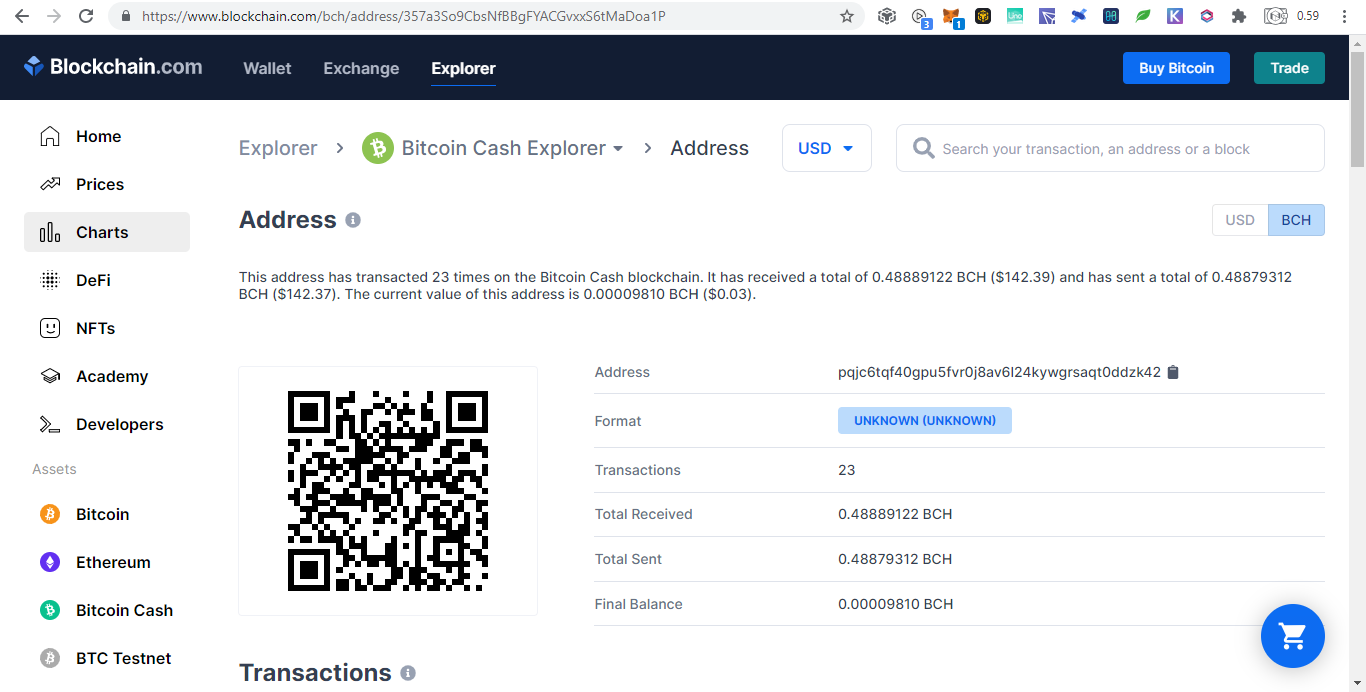
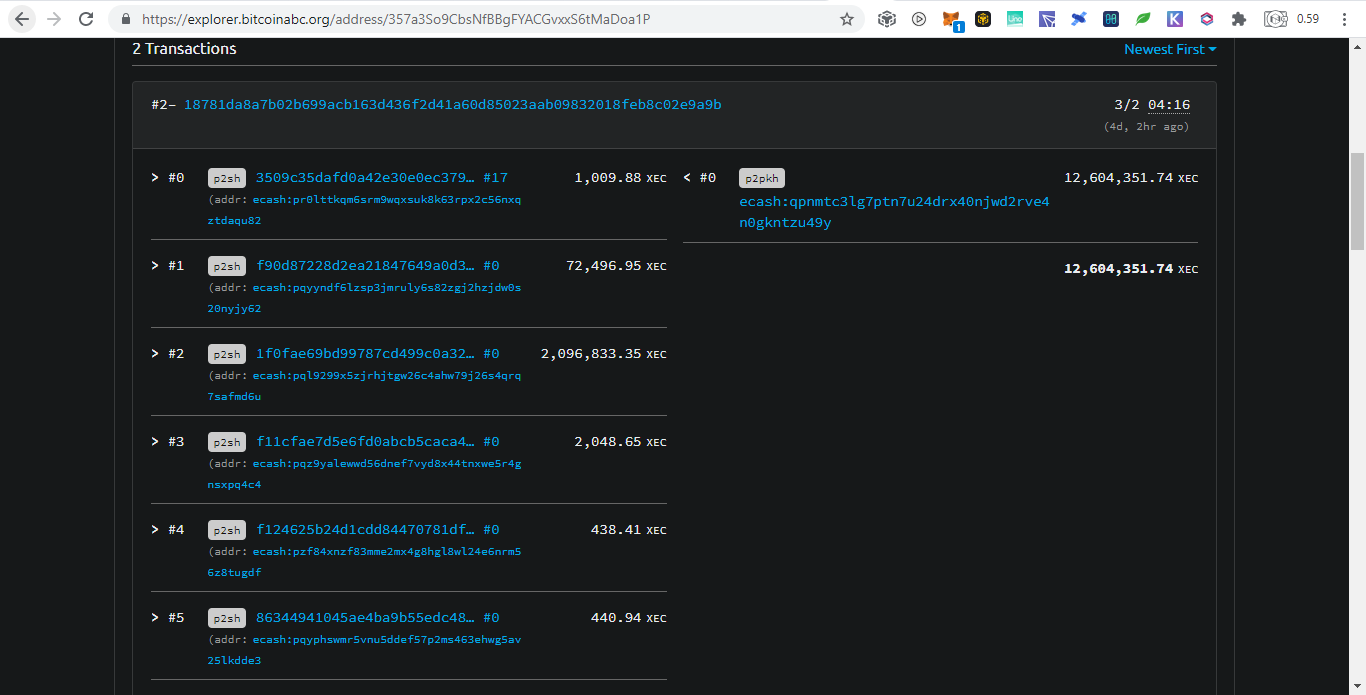
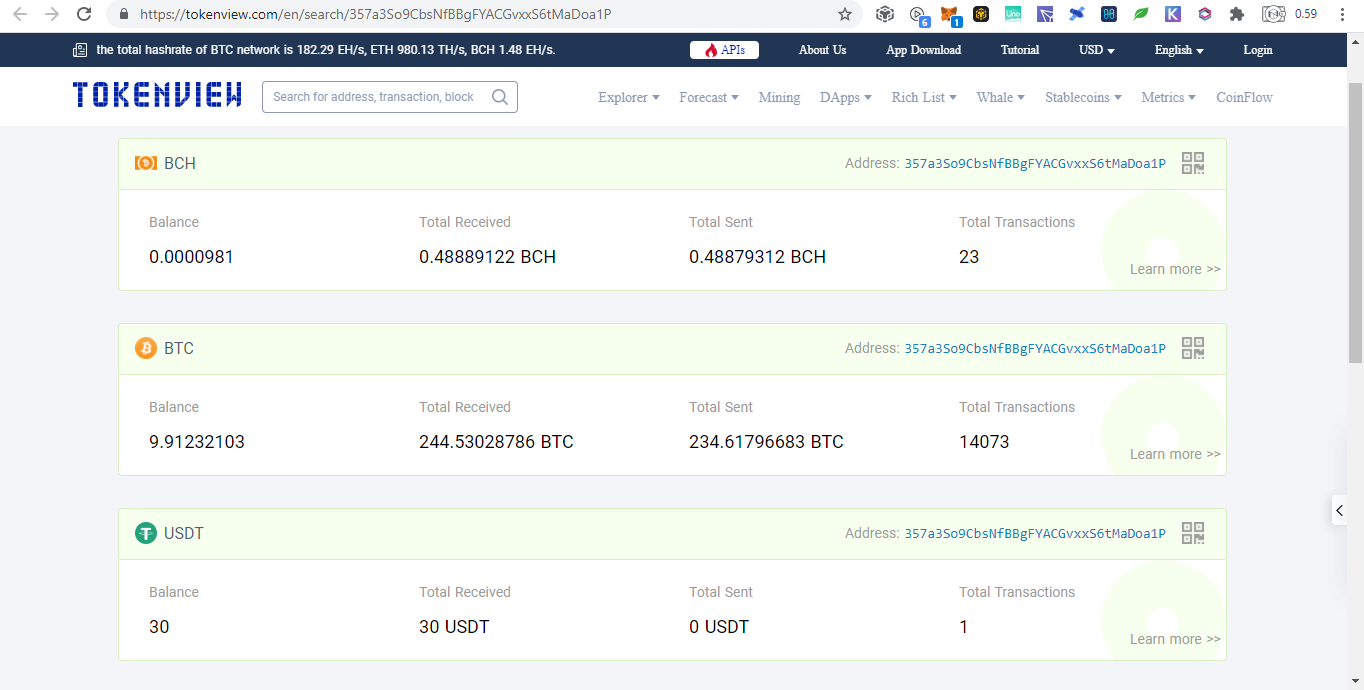
EVM CompatiblesHere is a good list of EVMs https://rpc.info/ and as before I will only list those that donated: 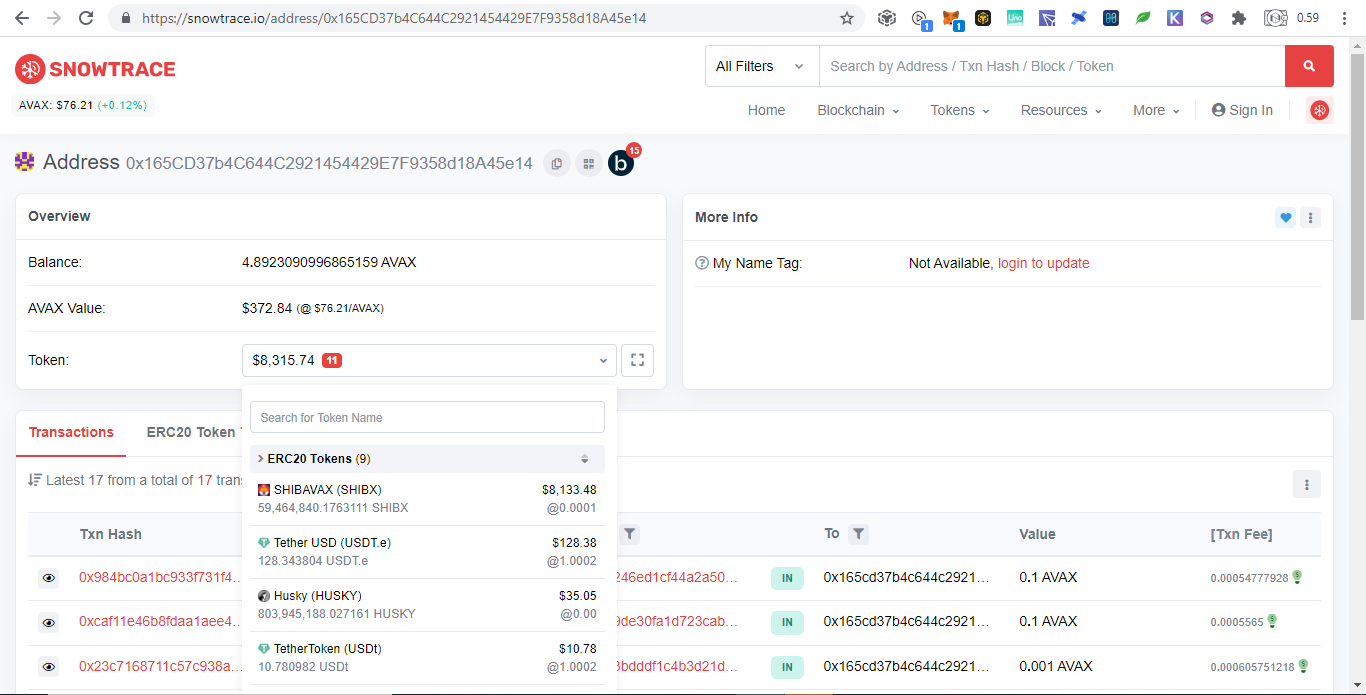
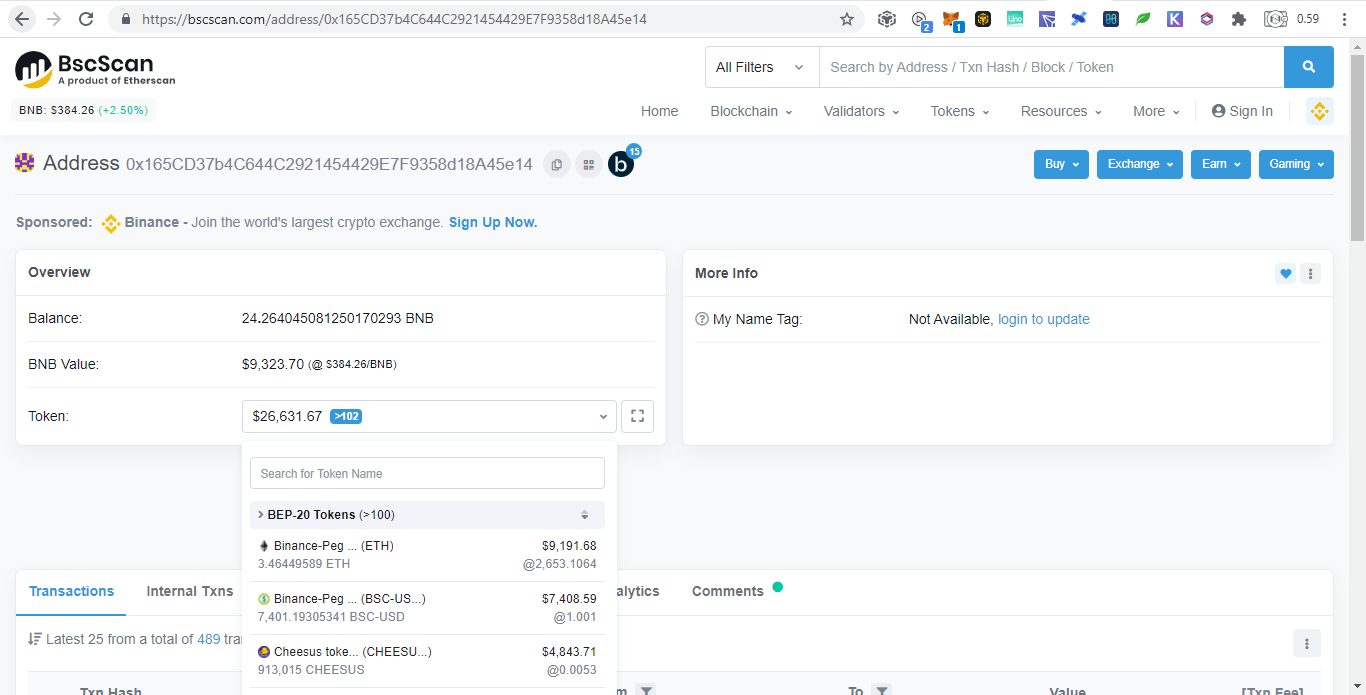
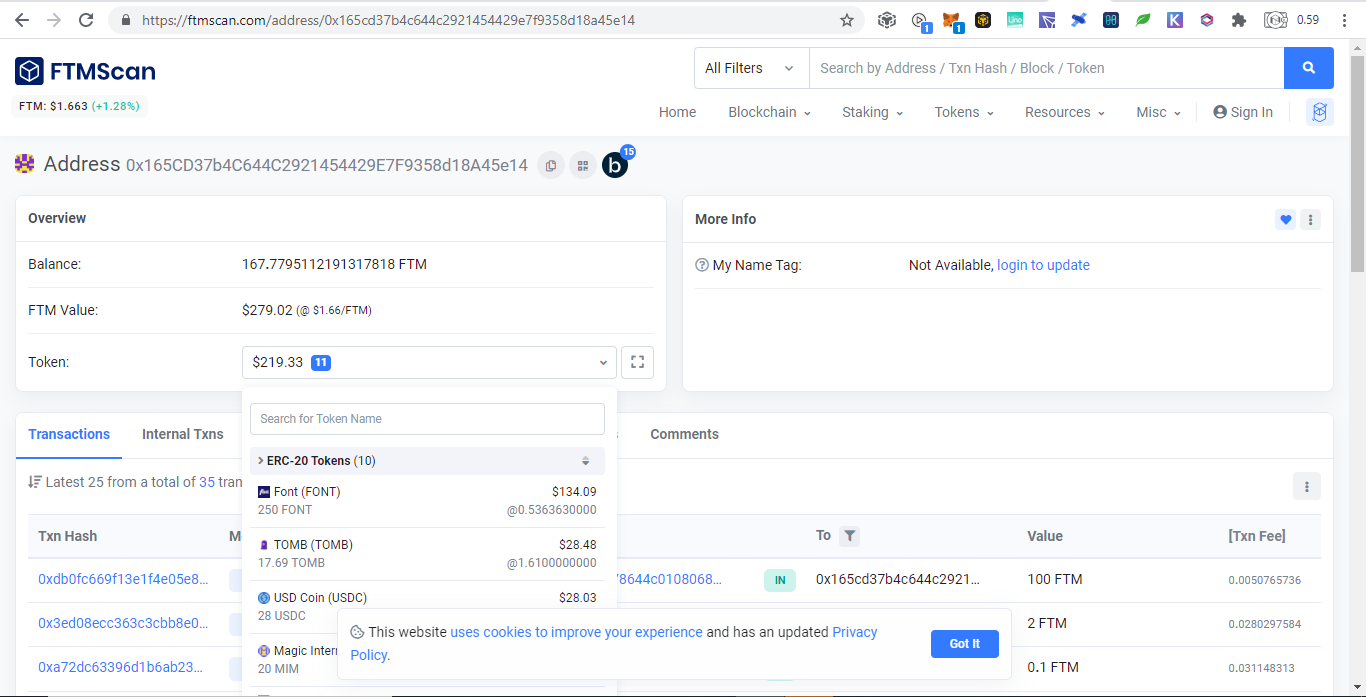
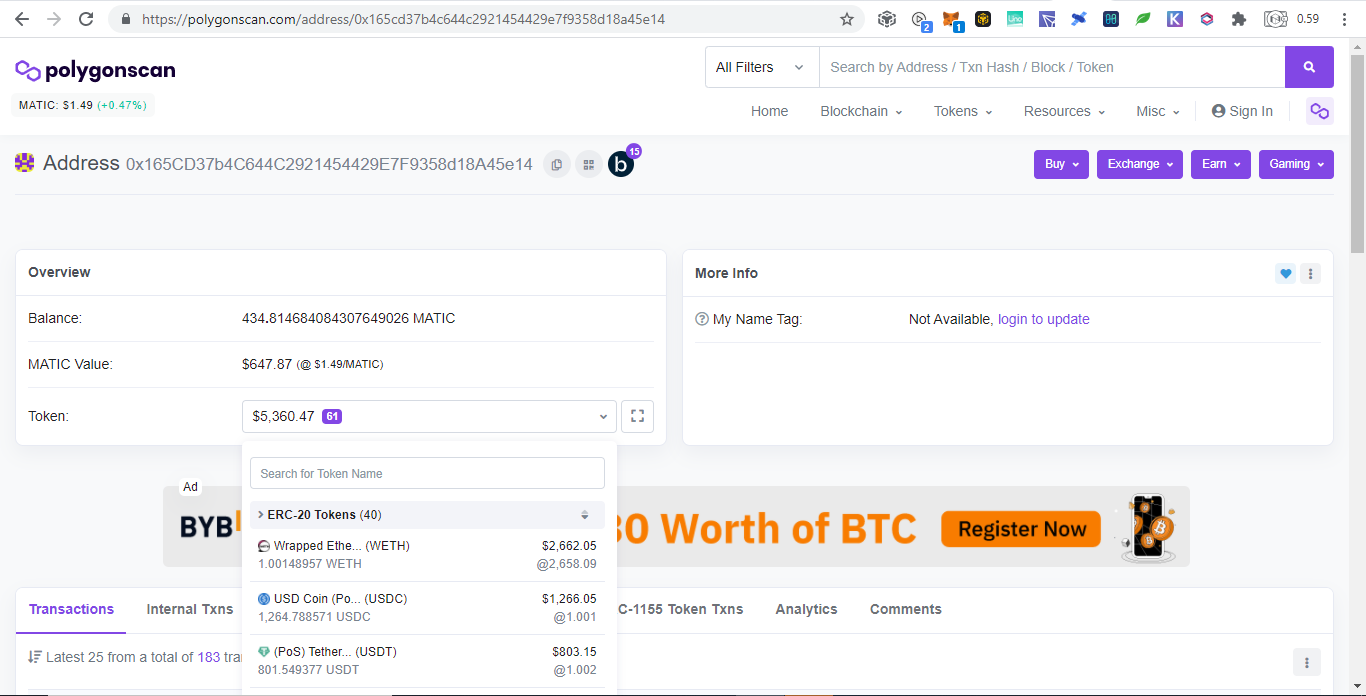
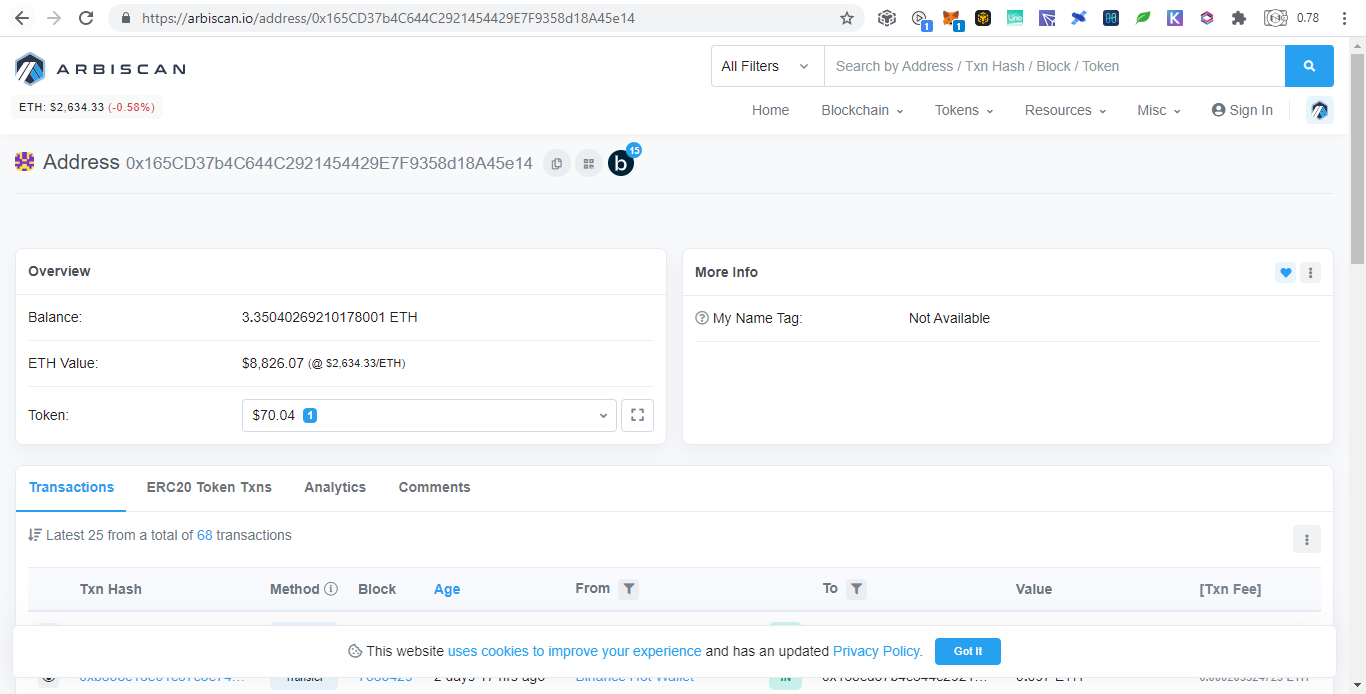
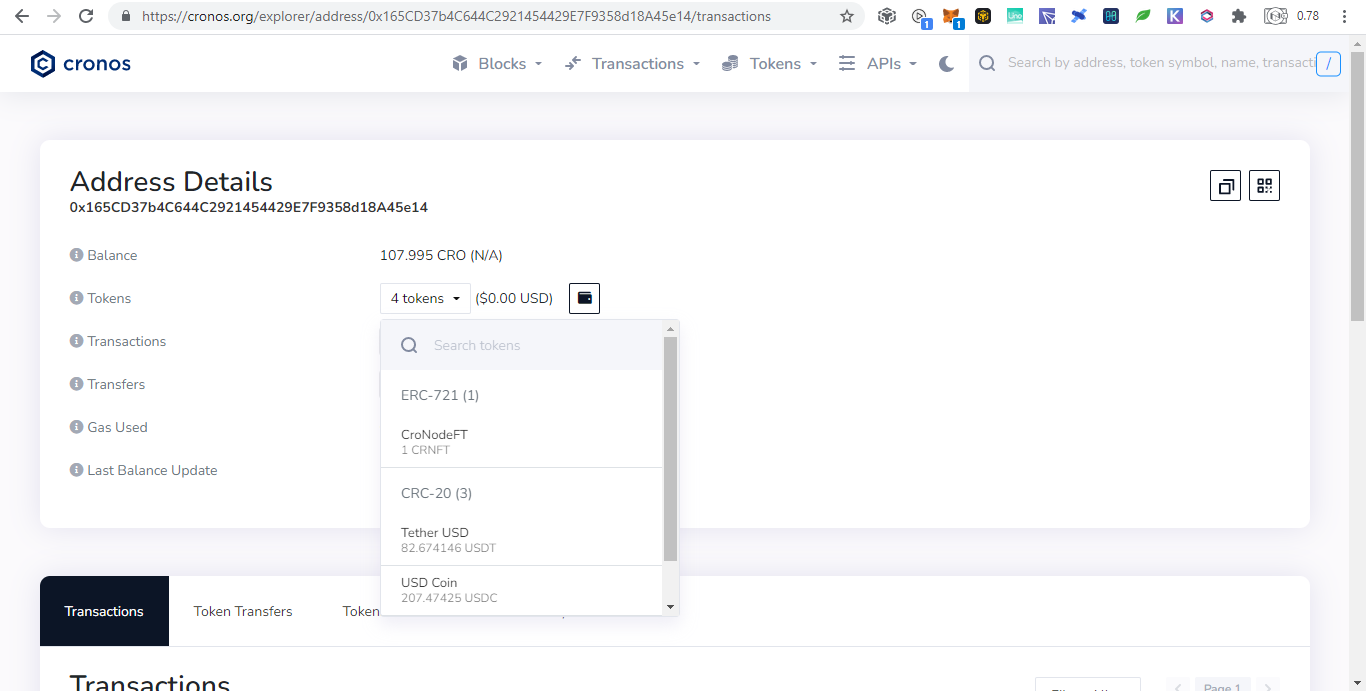
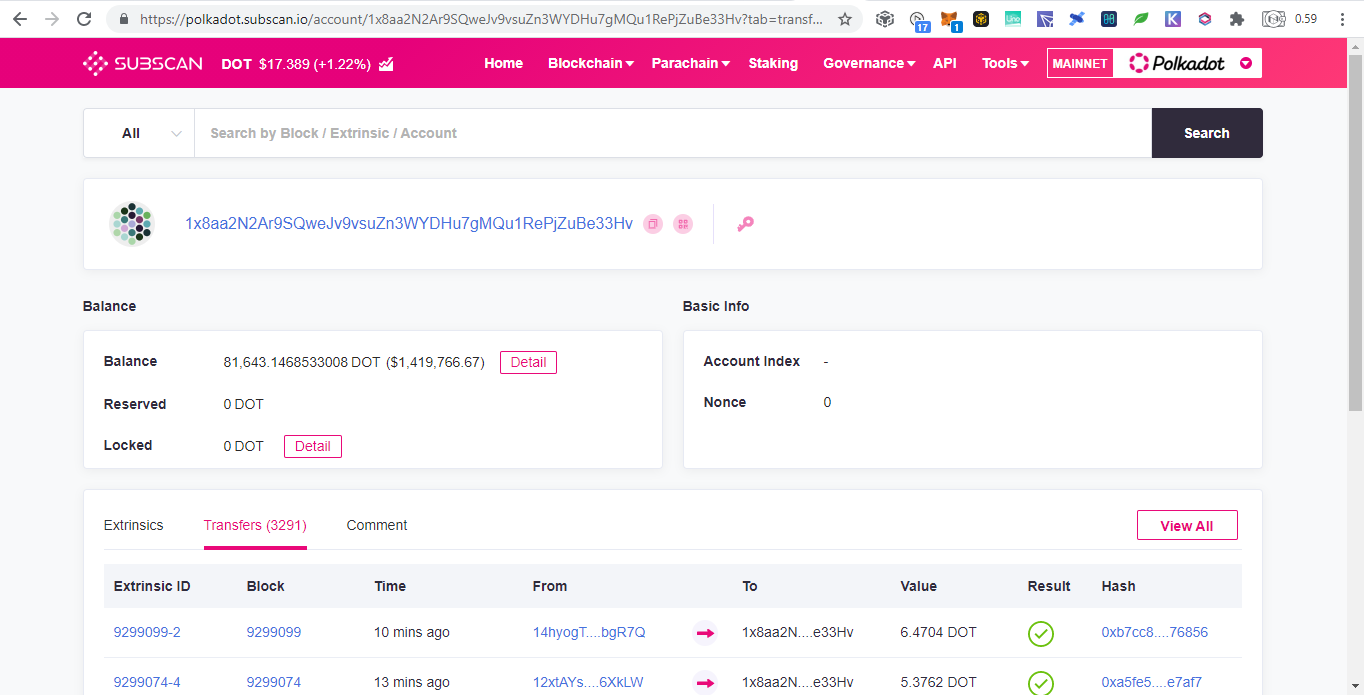
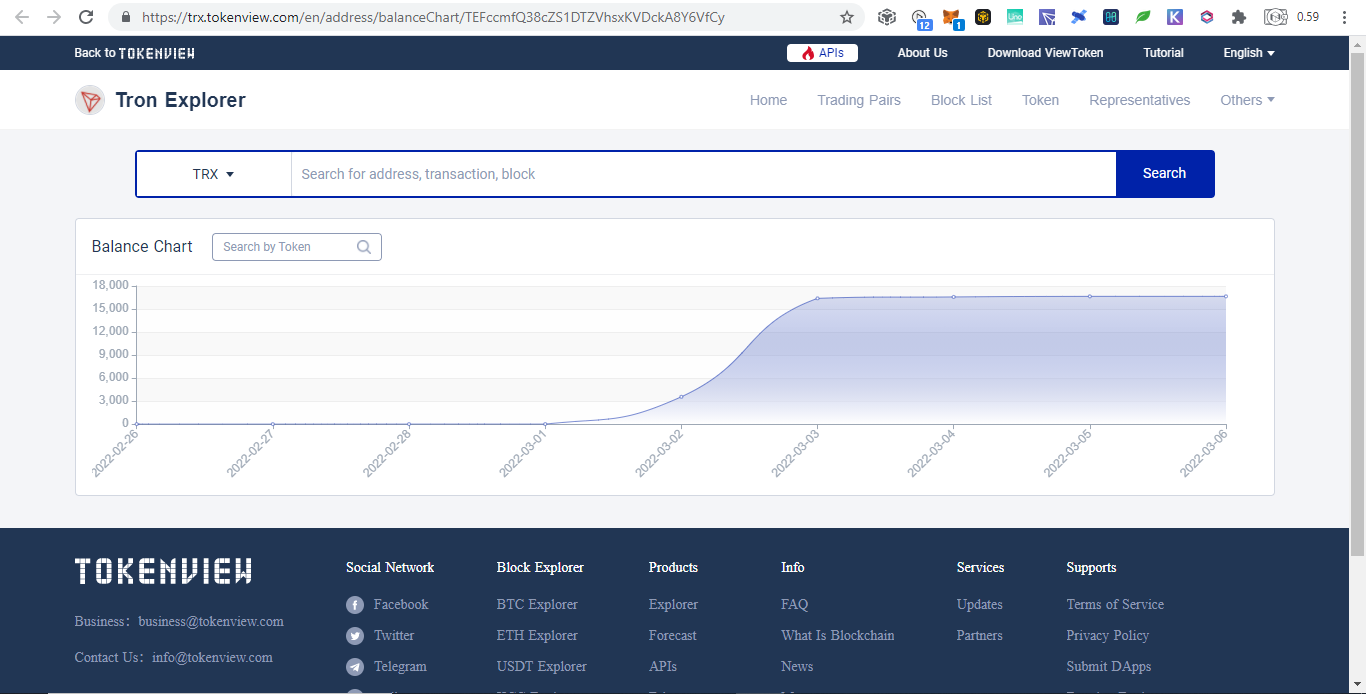
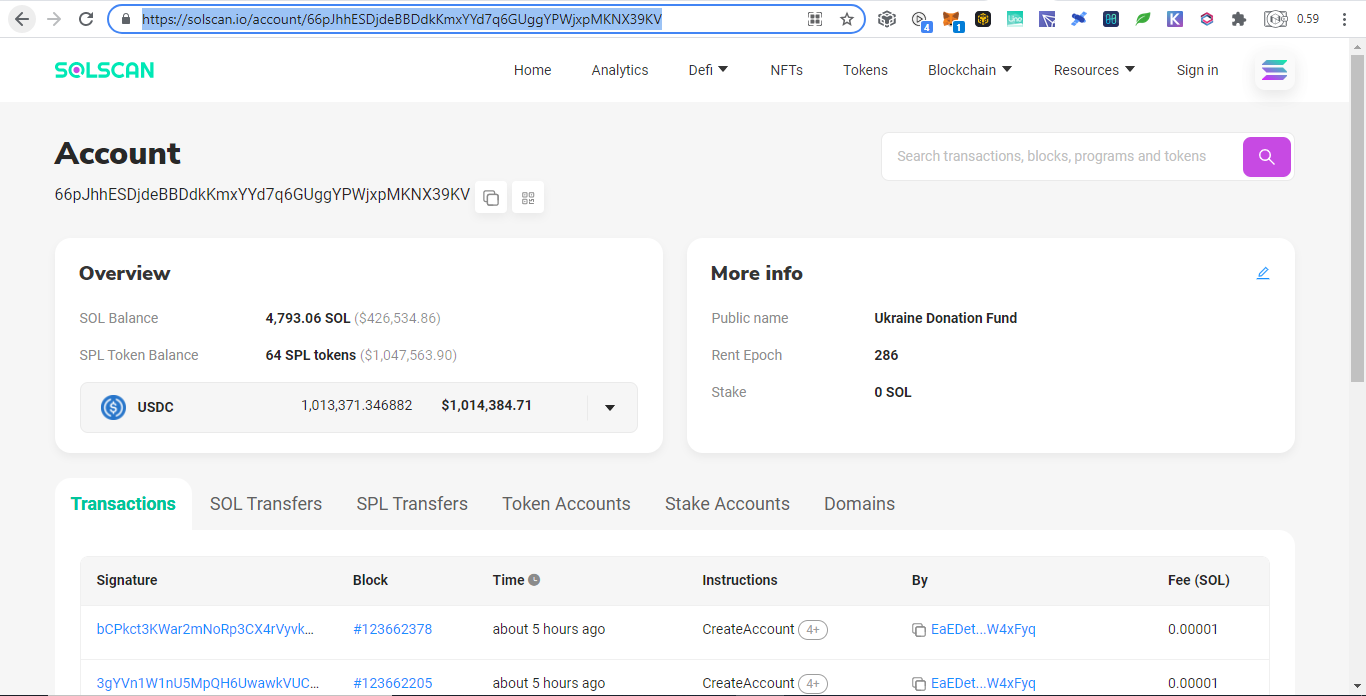
Below are donations below $20 and there are more but no donations made yet: Portfolio Trackers and GeneratorsWith the ever increasing chains and their tokens, it is very hard to keep track even using blockchain explorers as we need to open them one by one. Therefore developers takes the opportunity to develop portfolio trackers and generators to view all those chains in one place. Other than that, portfolio trackers provides more charts and graphics for average users to understand. As the saying goes, words are more understandable than codes, tables summarizes words, and pictures represents many words. The full node for experts to view are like words, the blockchain explorers are like tables which is easier to understand but still technical which is not favored by average users, while portfolio trackers are like images that just a glimpse and everyone understands. Below are some shareable portfolio trackers also showing Ukraine's donation addresses: 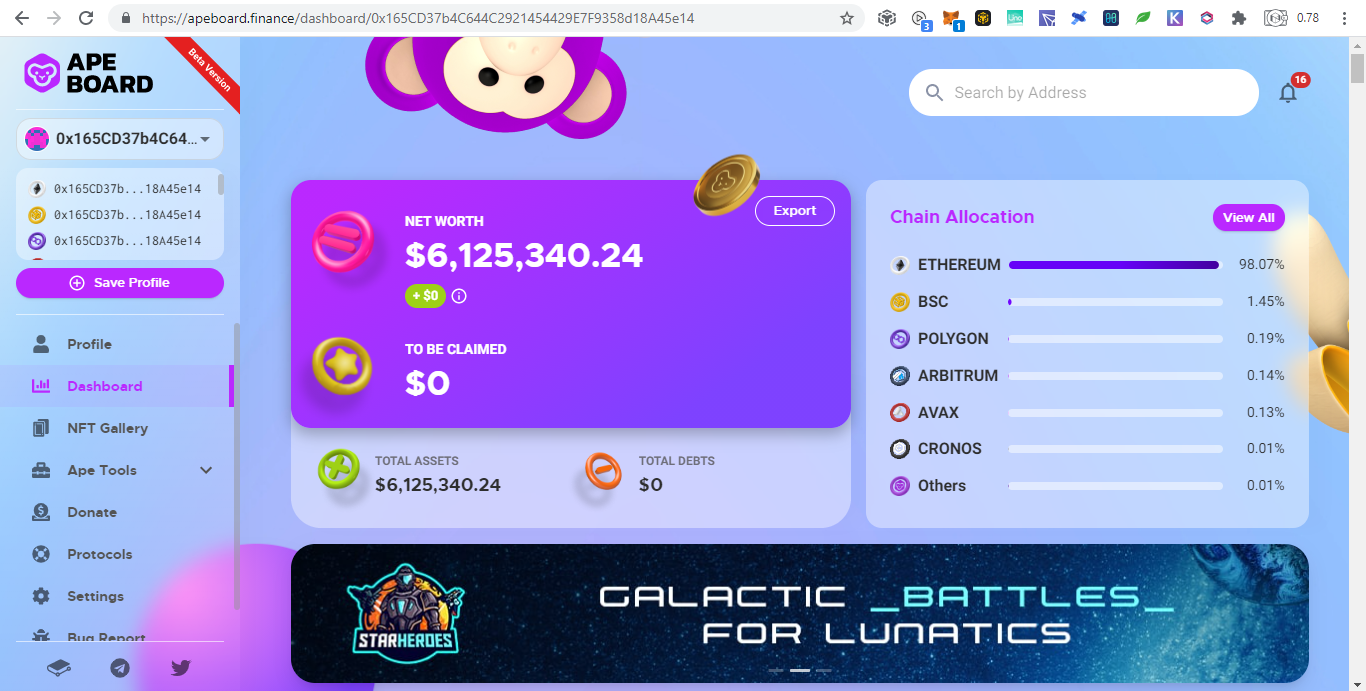
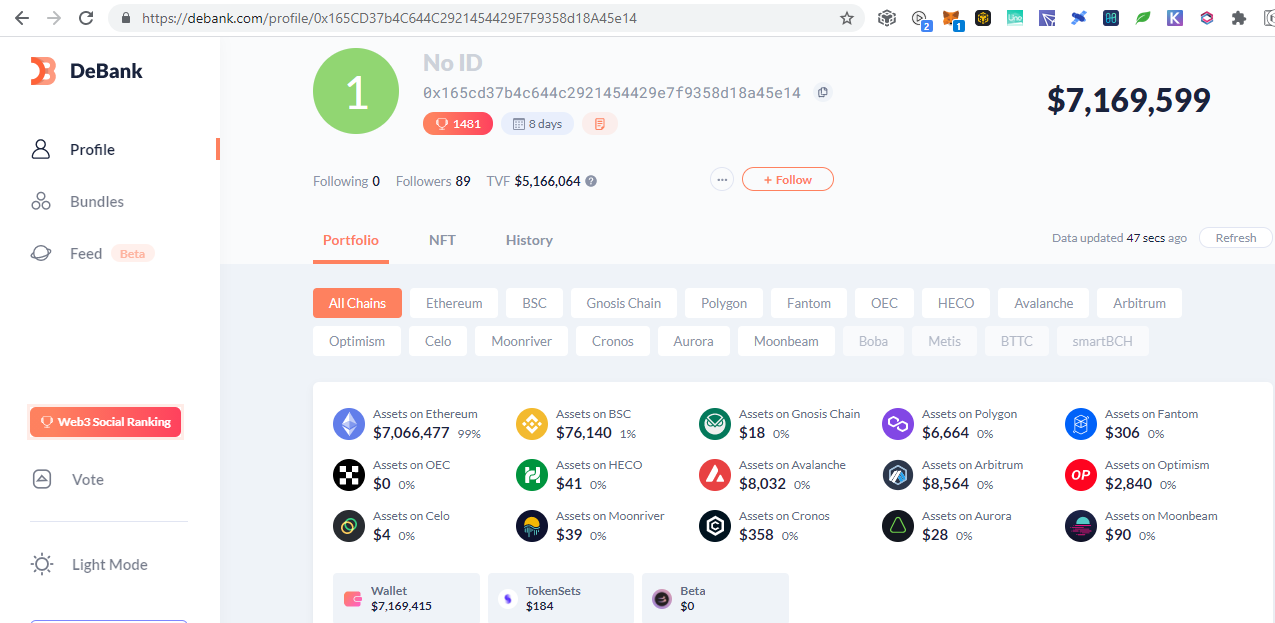
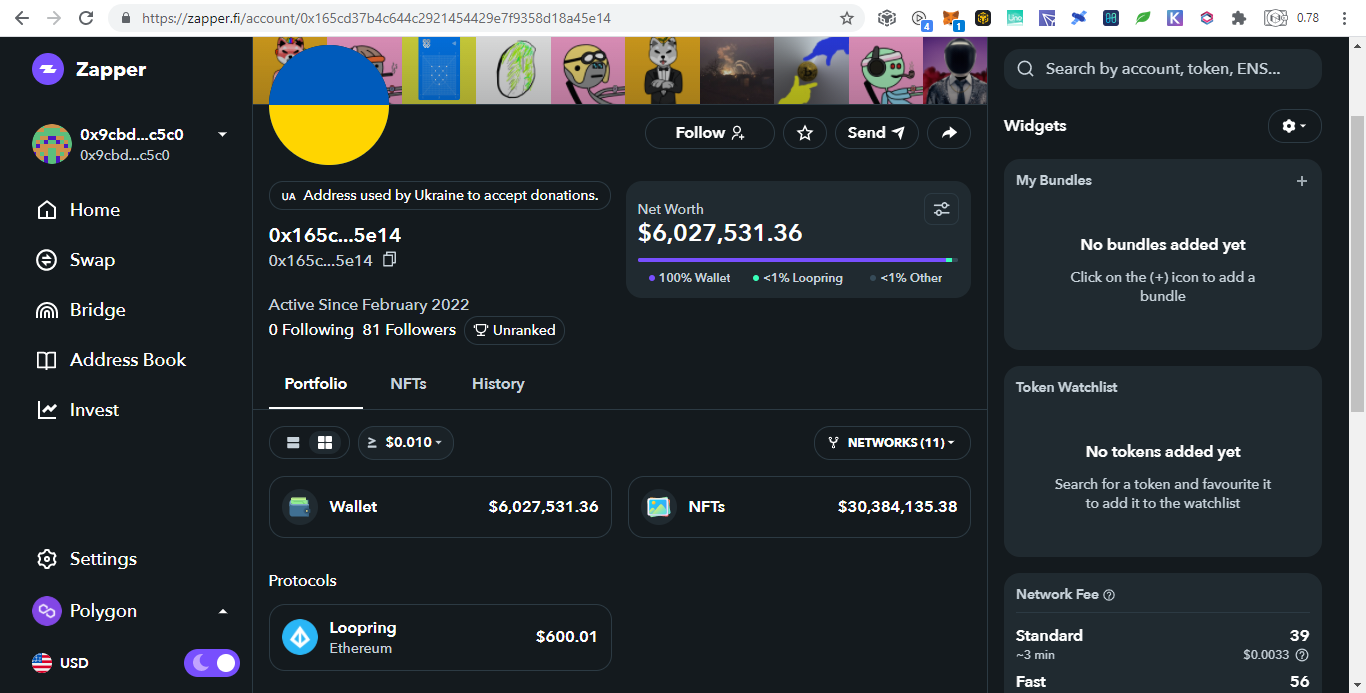
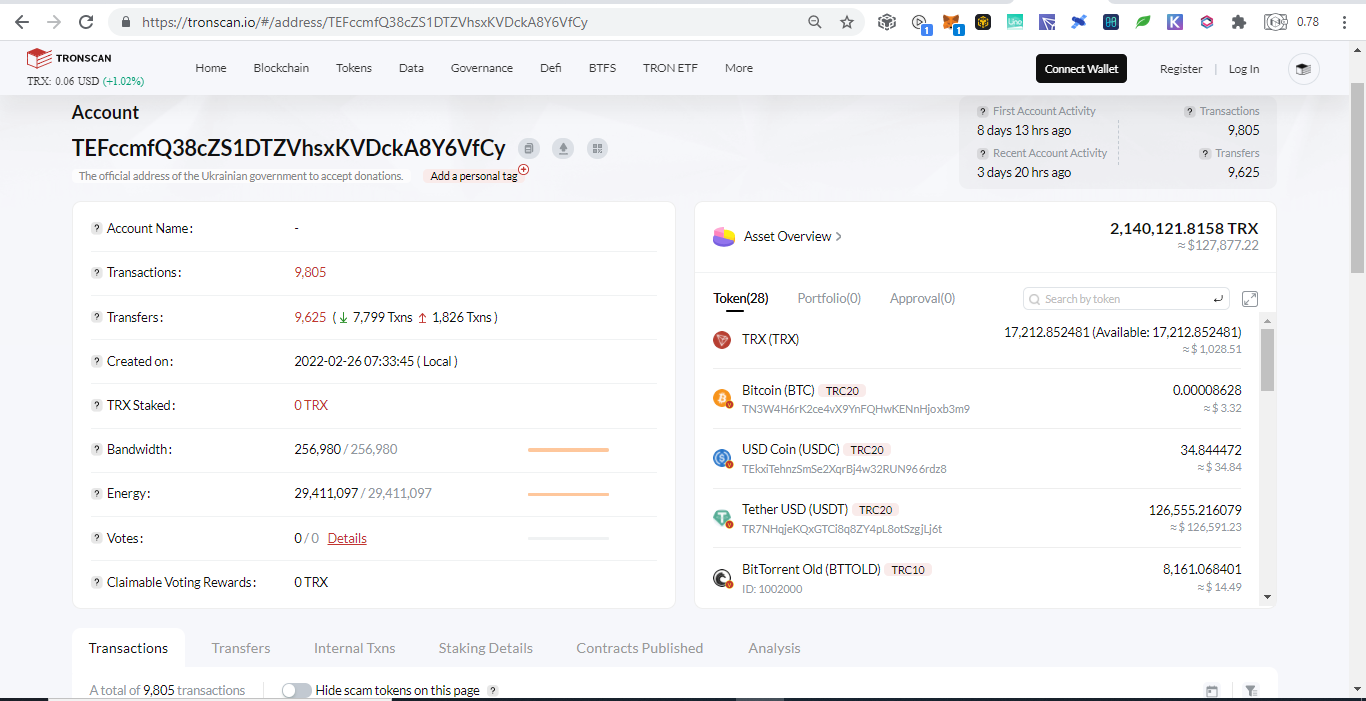
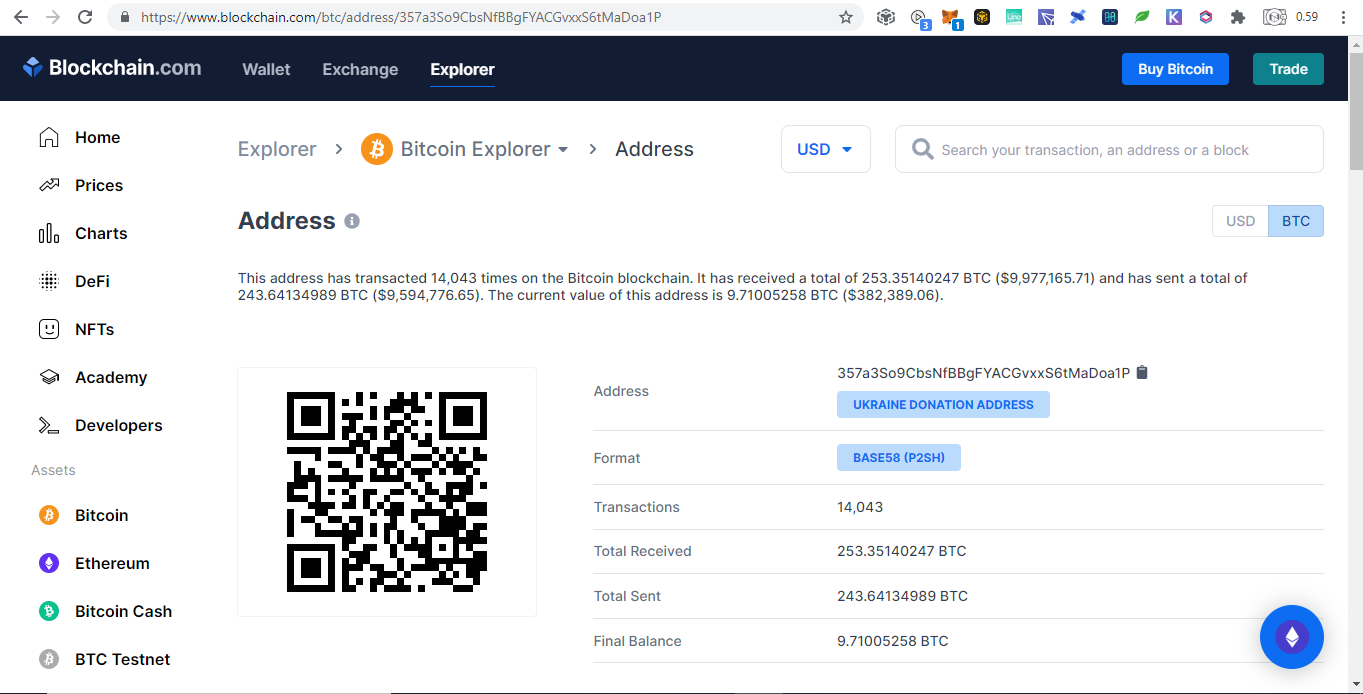
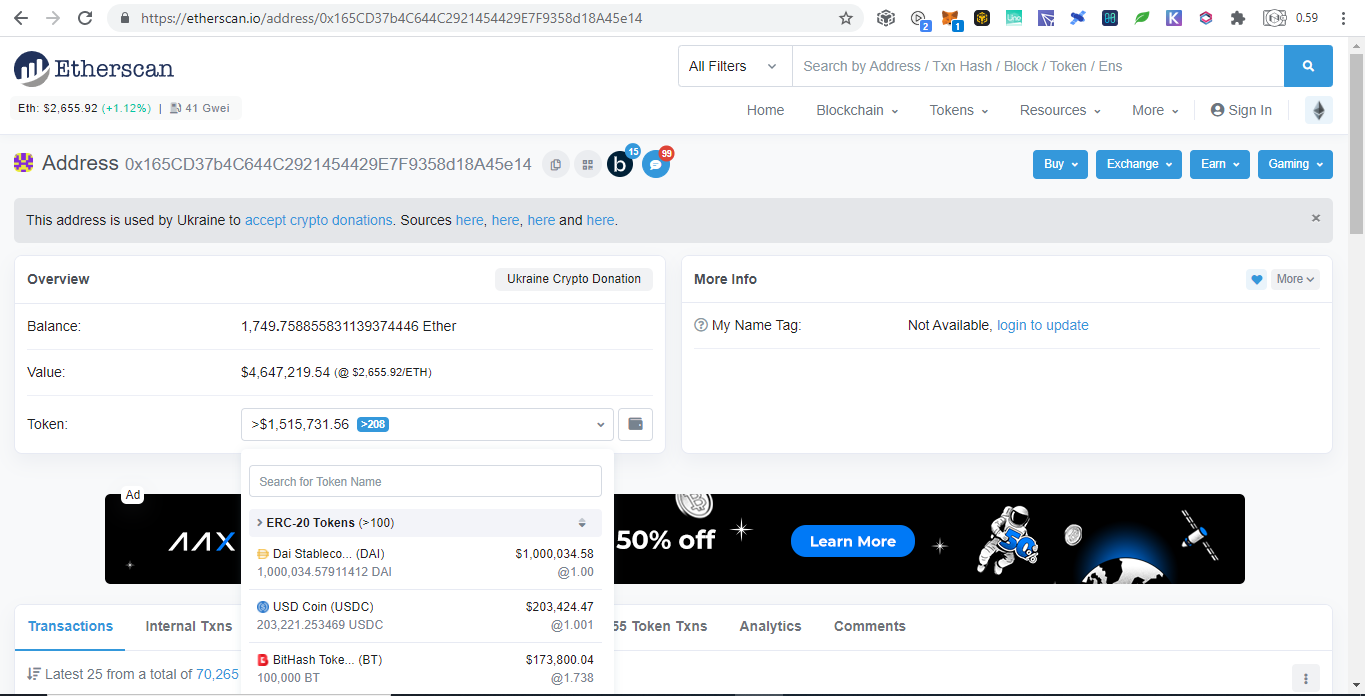
SummaryWith the transparency of cryptocurrency, even you can track donations to Ukraine by simply browsing the web. Until now there are $15M native coins and countless tokens that can explode on the next altcoin season donated. Donating in the crypto space is simple, scan and send.
 Mobile Wallets To Access DAPP Main Network and Smart Chain are on Same Network Portfolio Generator or Tracker for Zilliqa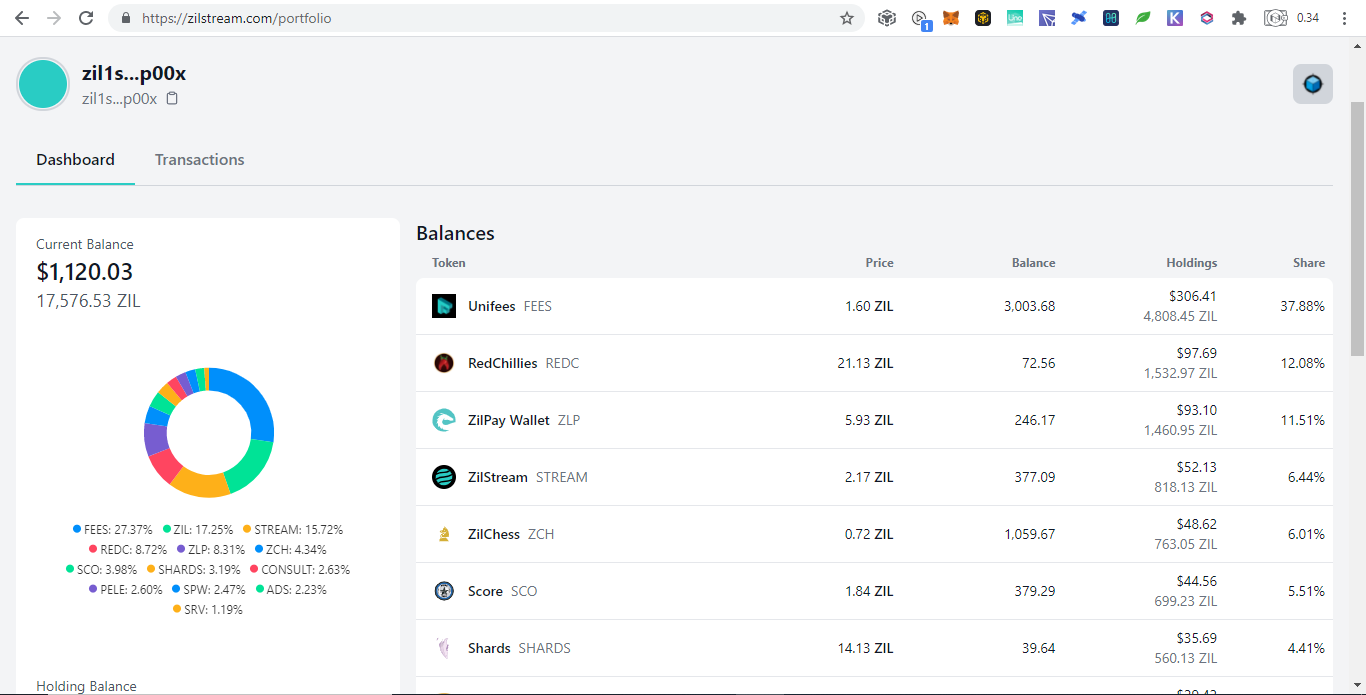 Trading View for Zilliqa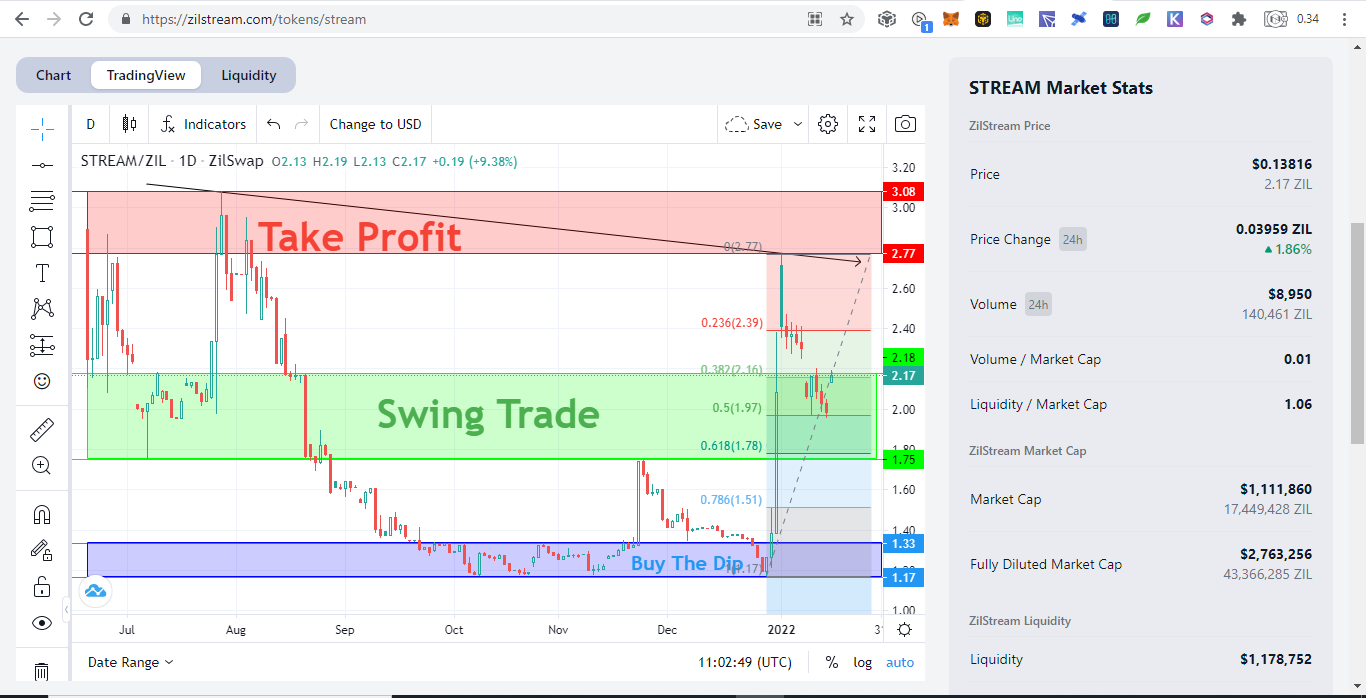 Mirrors

The Talent Industry

Problem in the Industry
Rumors of Mafia in the Industry
They are not even the main problem
Jetcoin aims to solve this problem
Mirrors
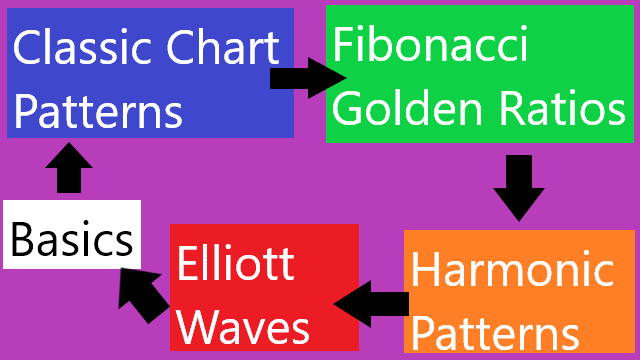
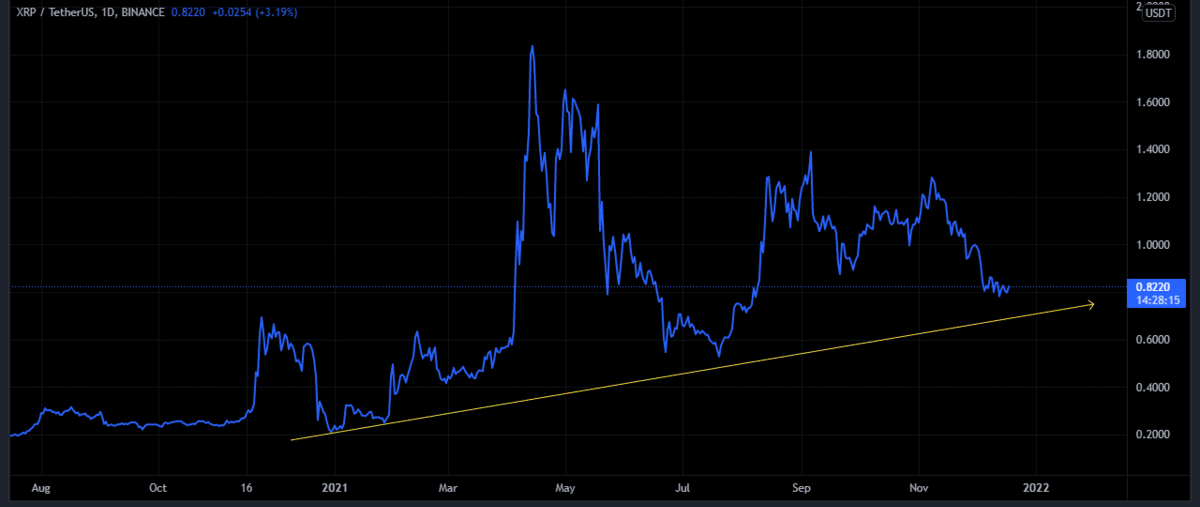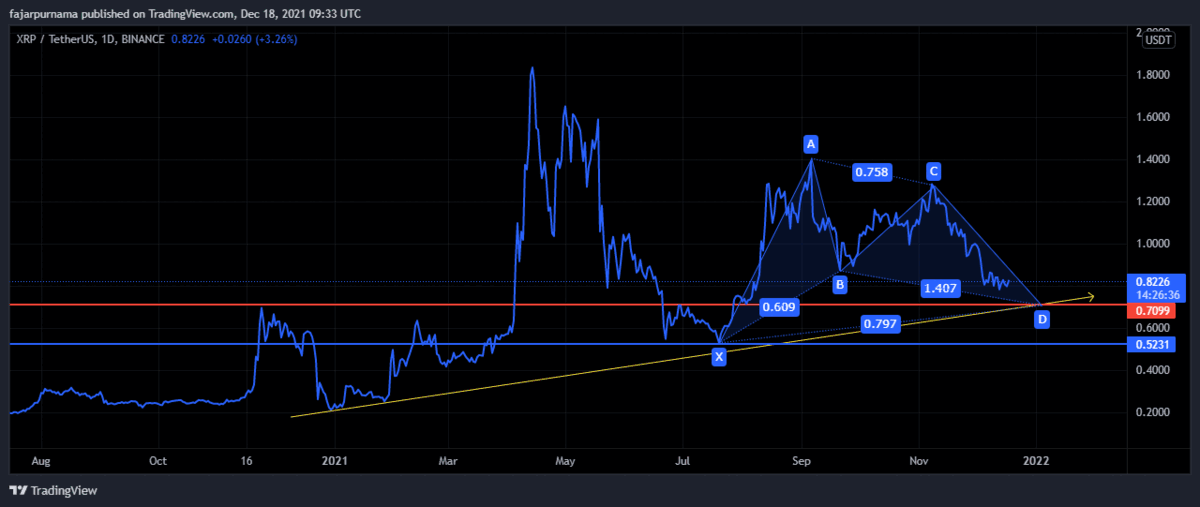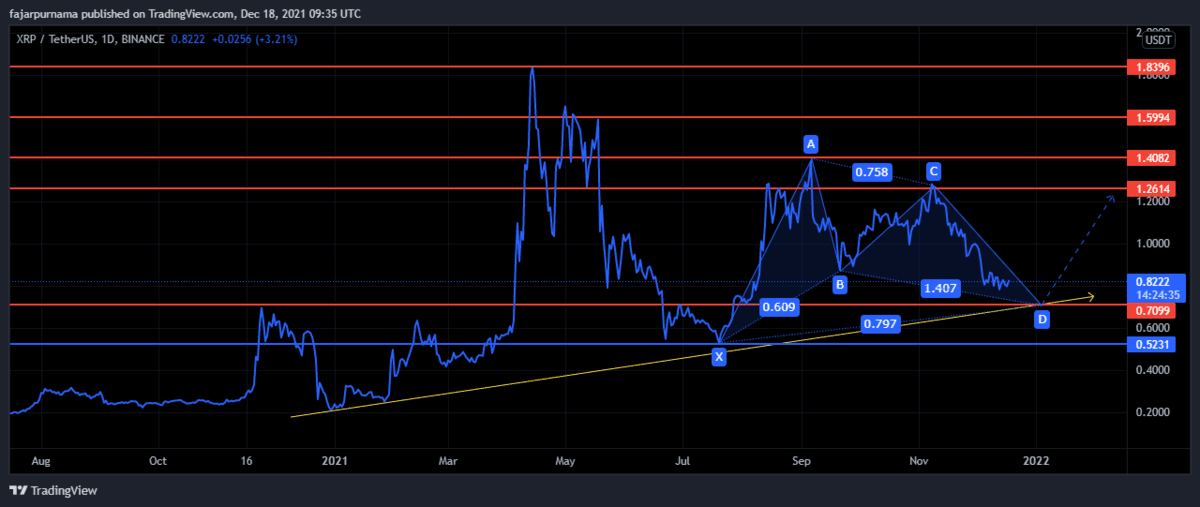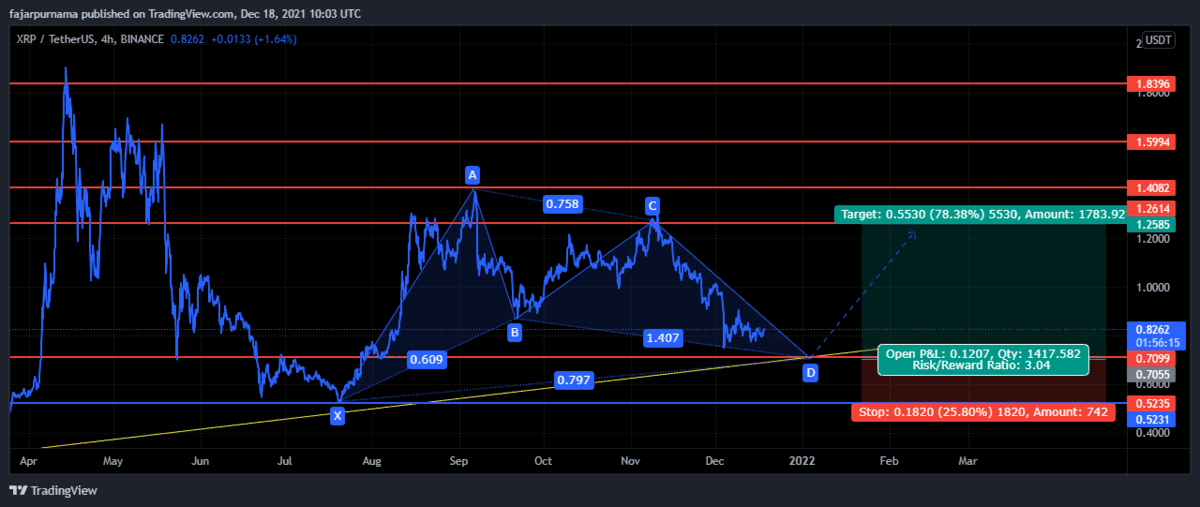
5. Classic Chart Patterns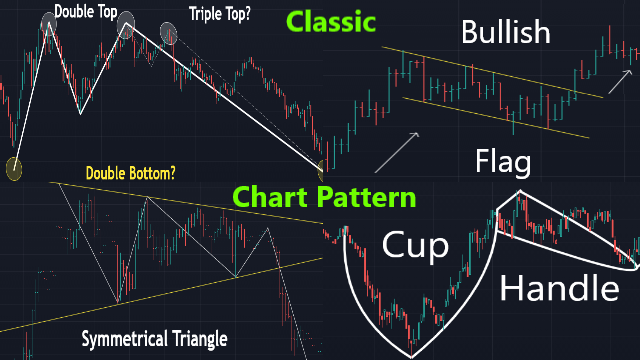
Continuous Patterns
Reversal Patterns
Either Patterns
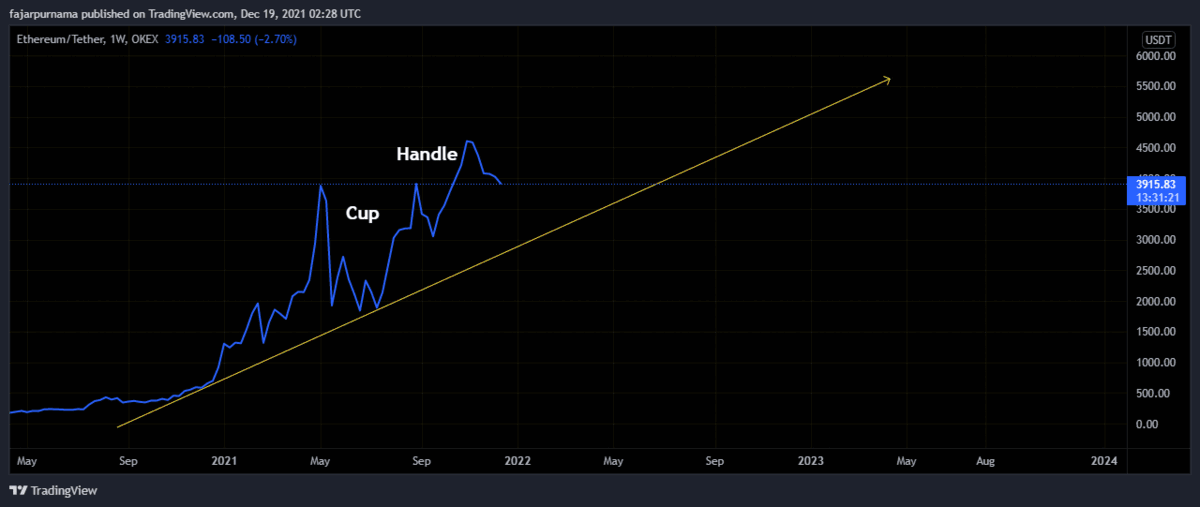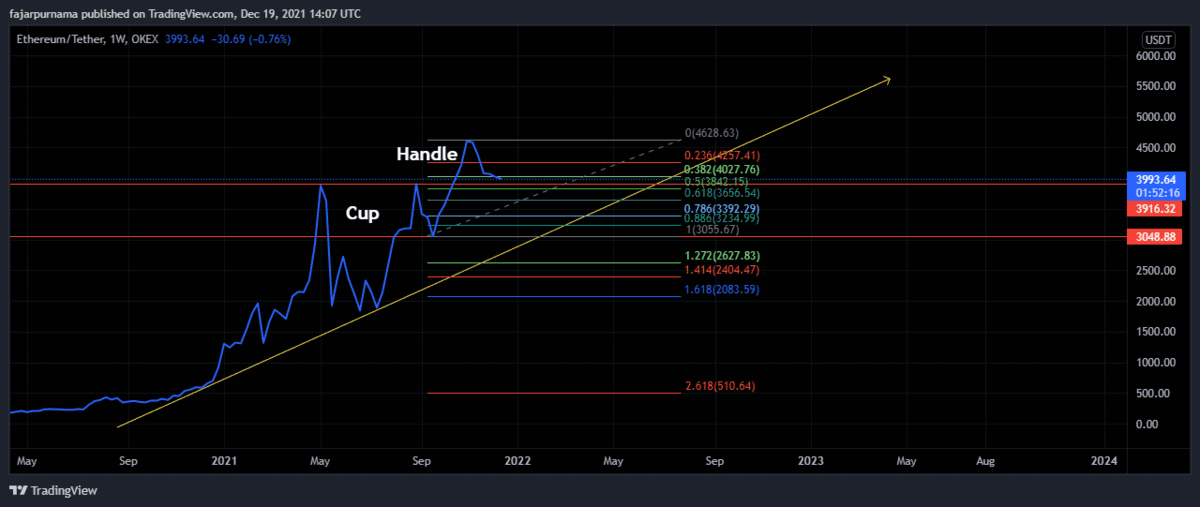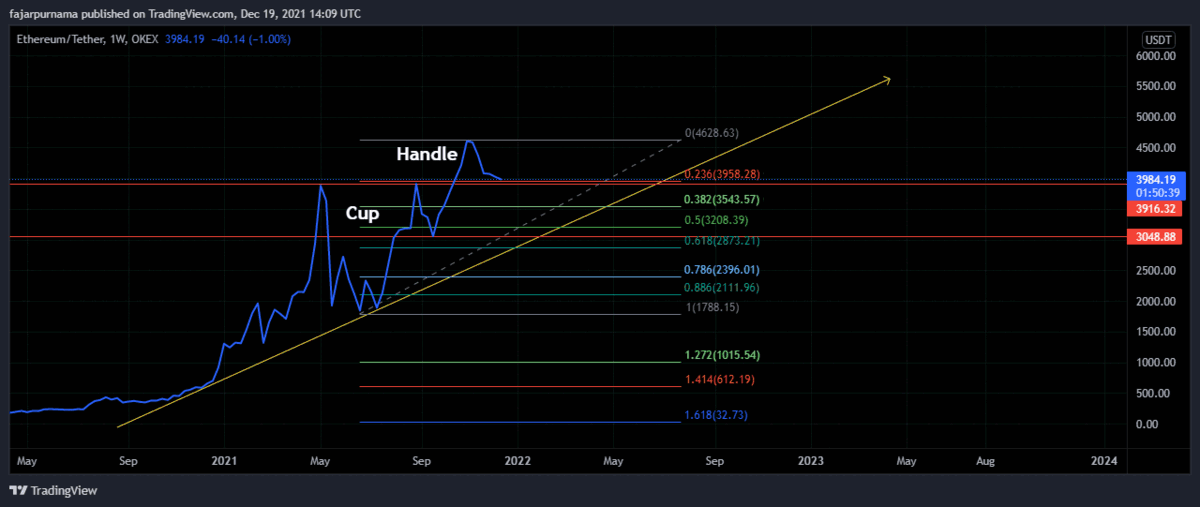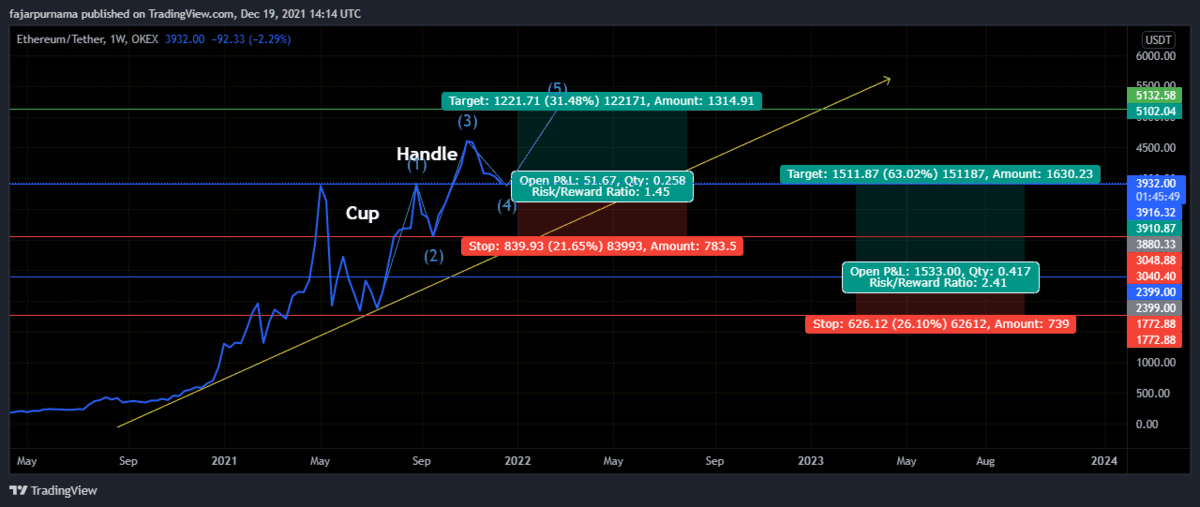
6. Fibonacci Golden Ratios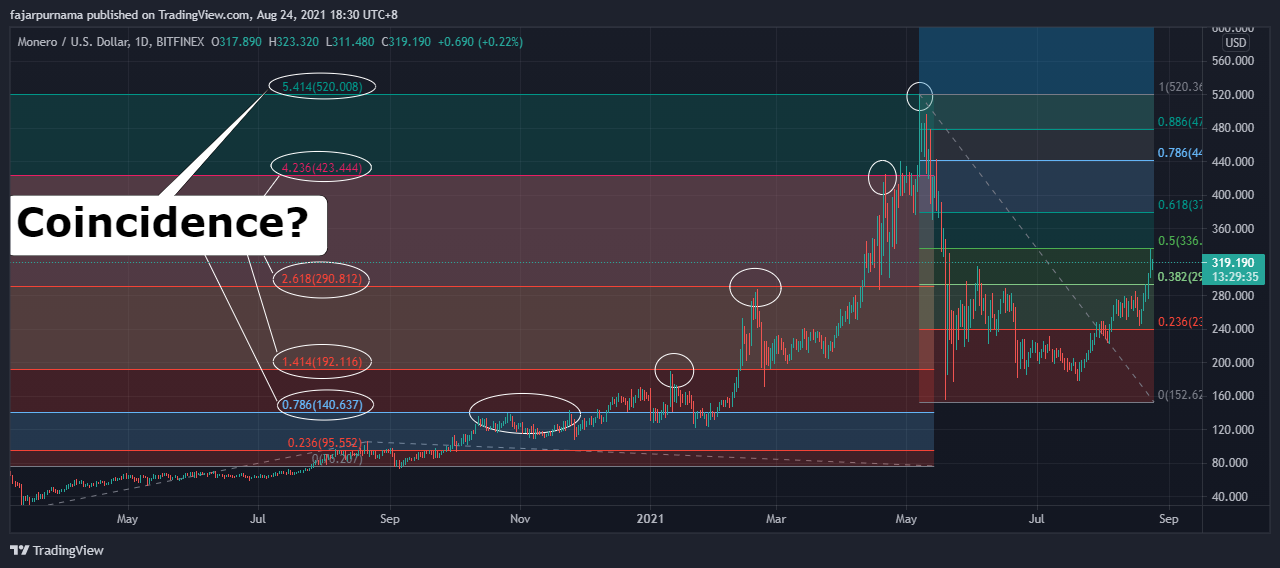
7. Harmonic Patterns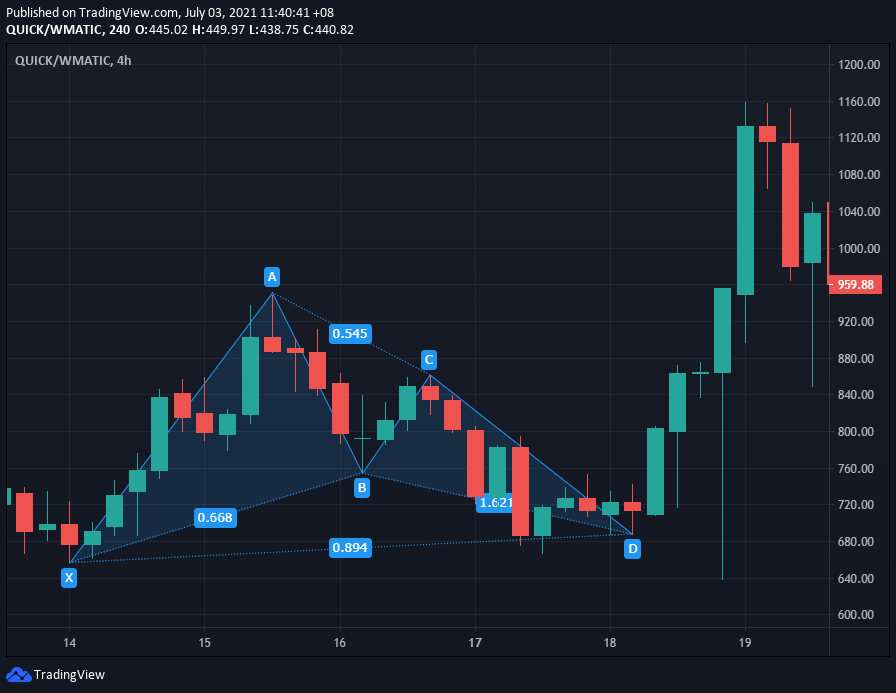
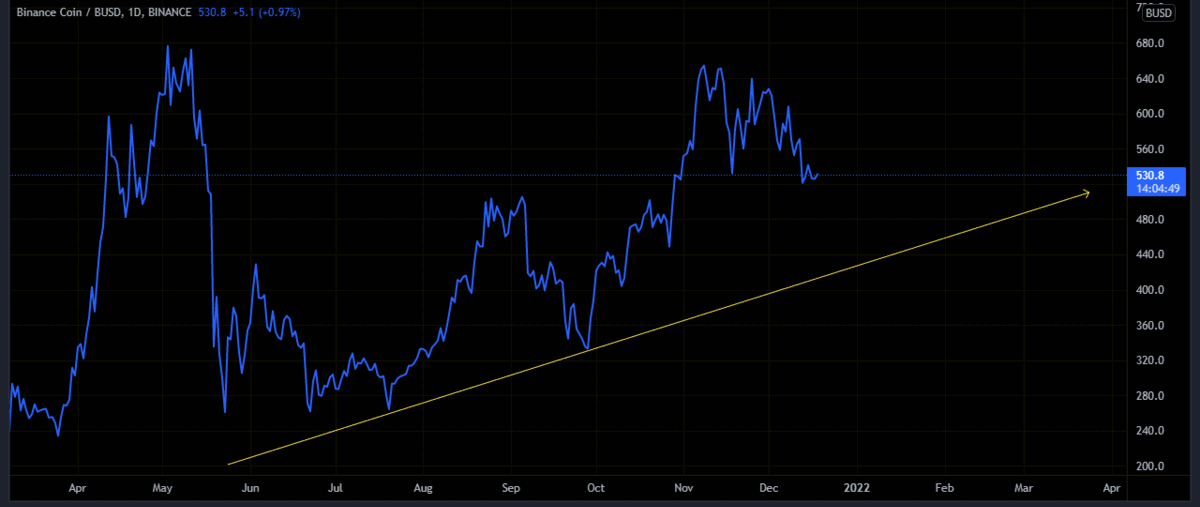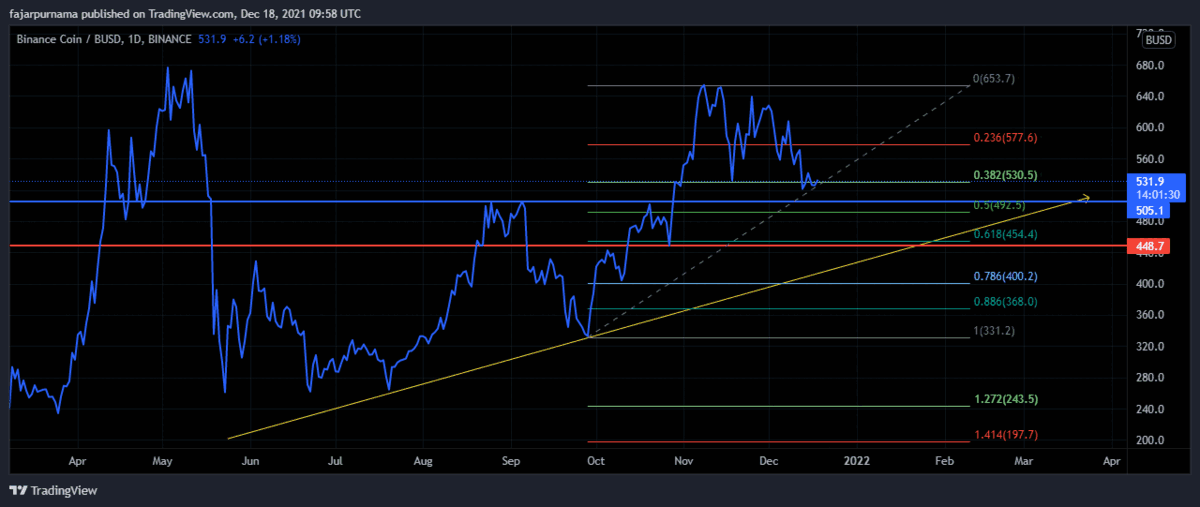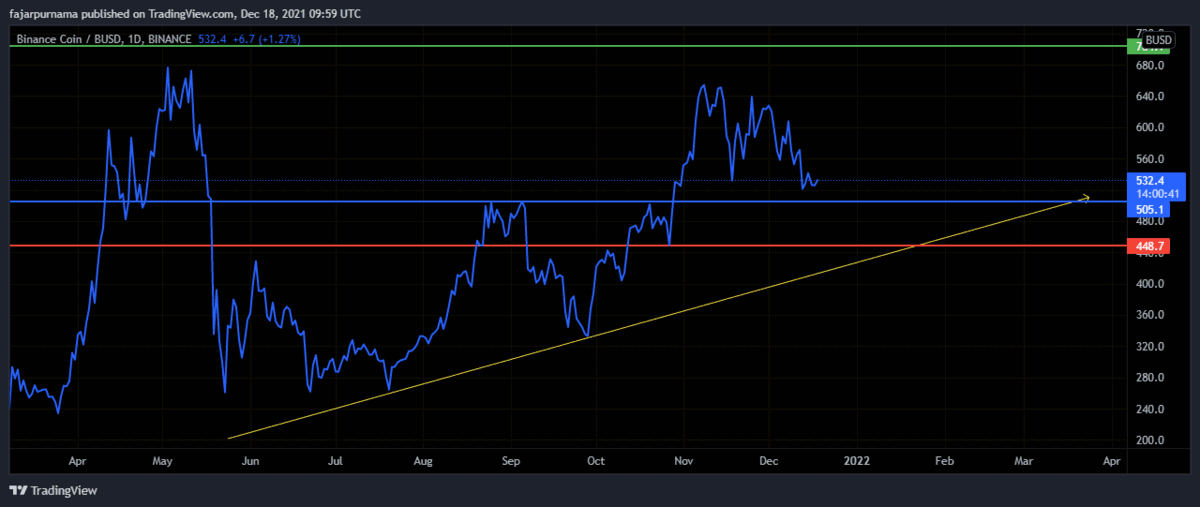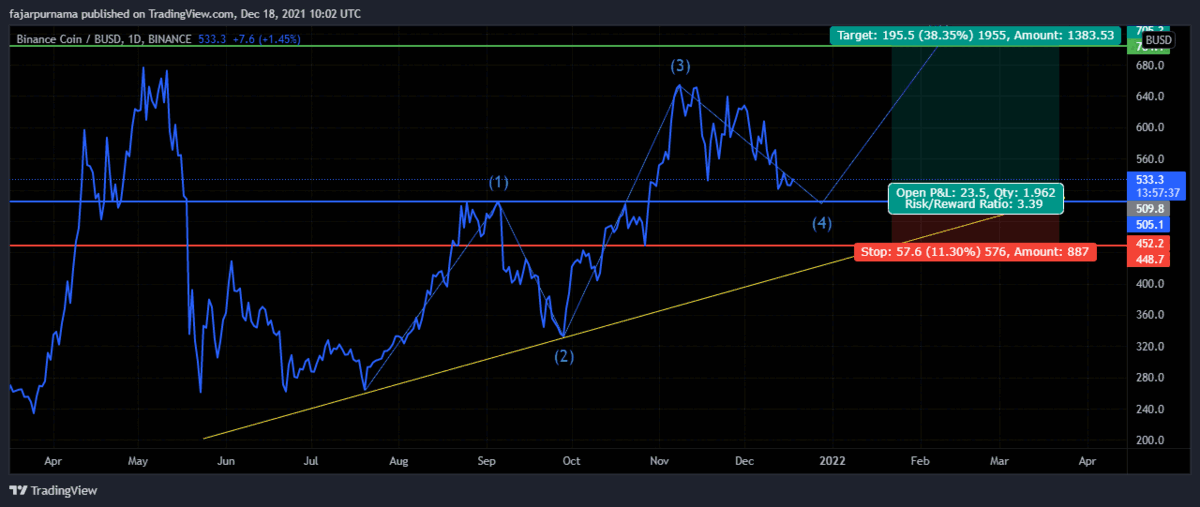
8. Elliott Wave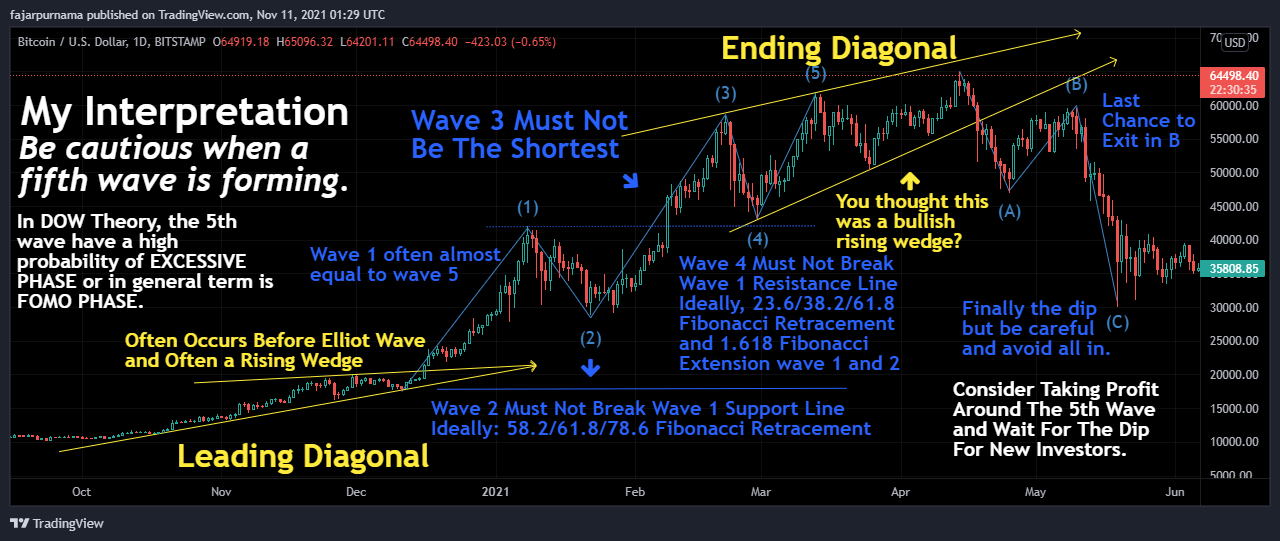
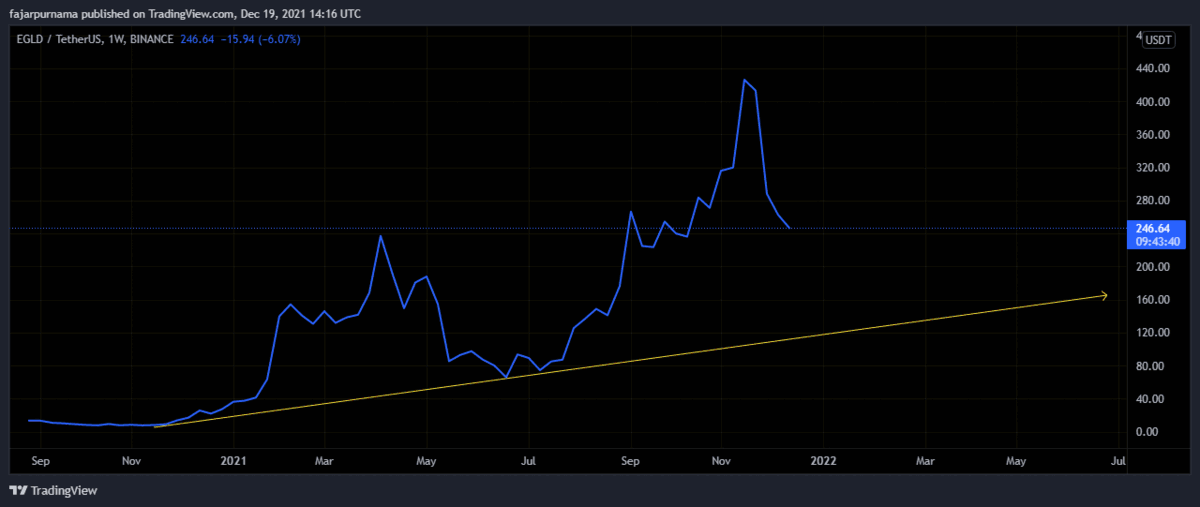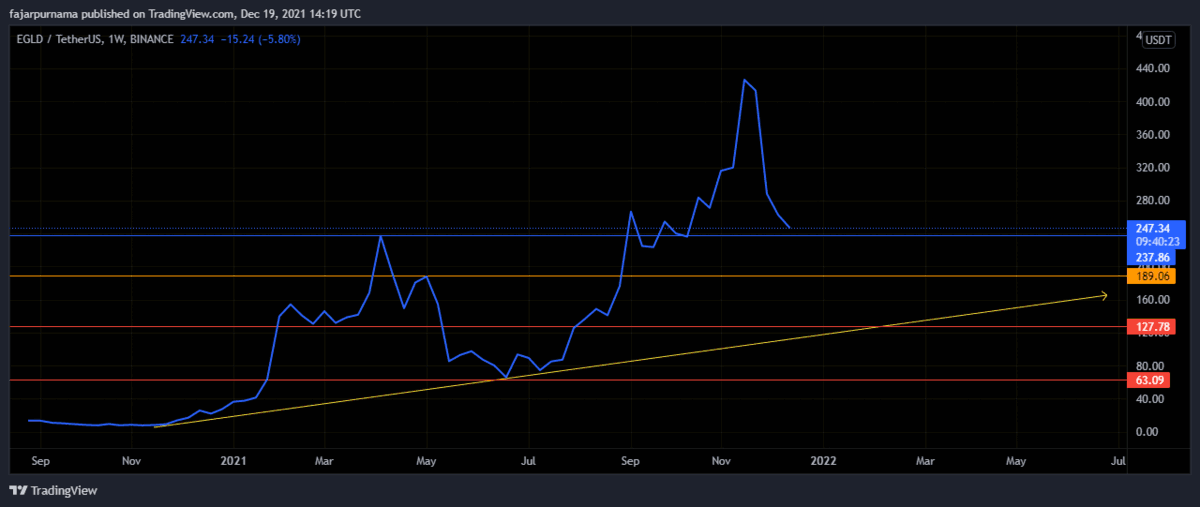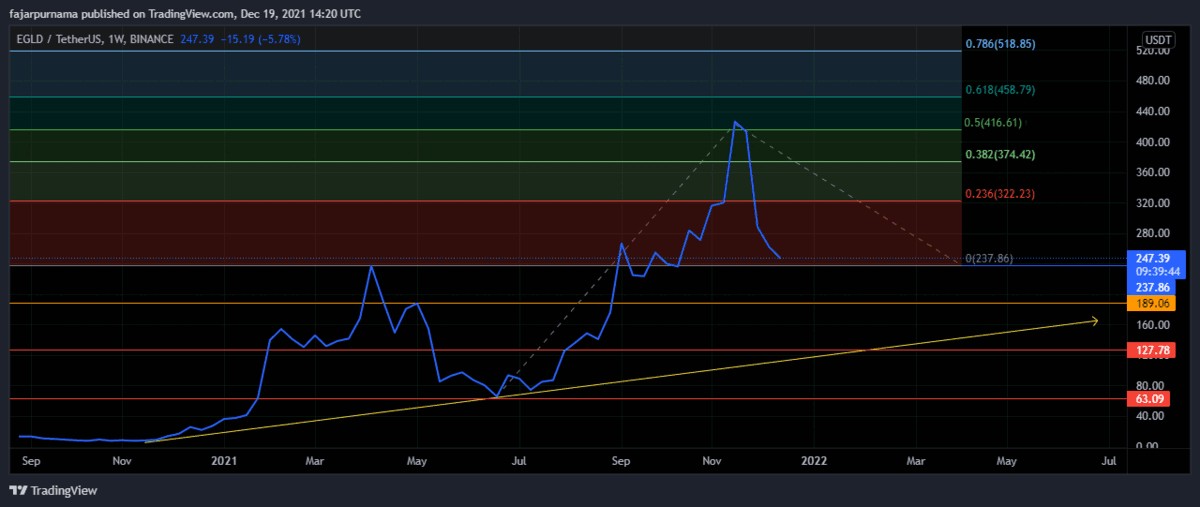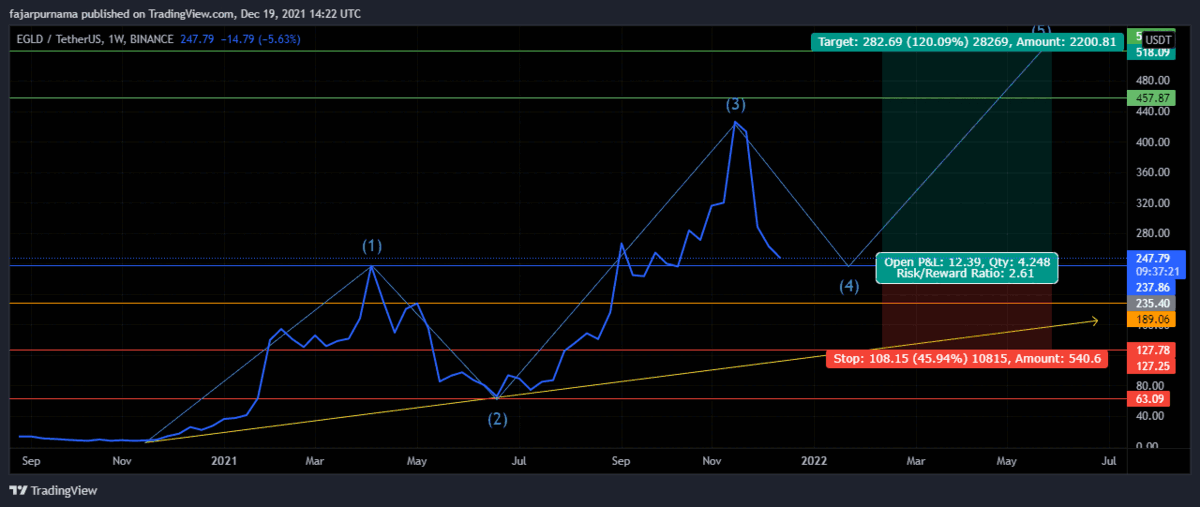
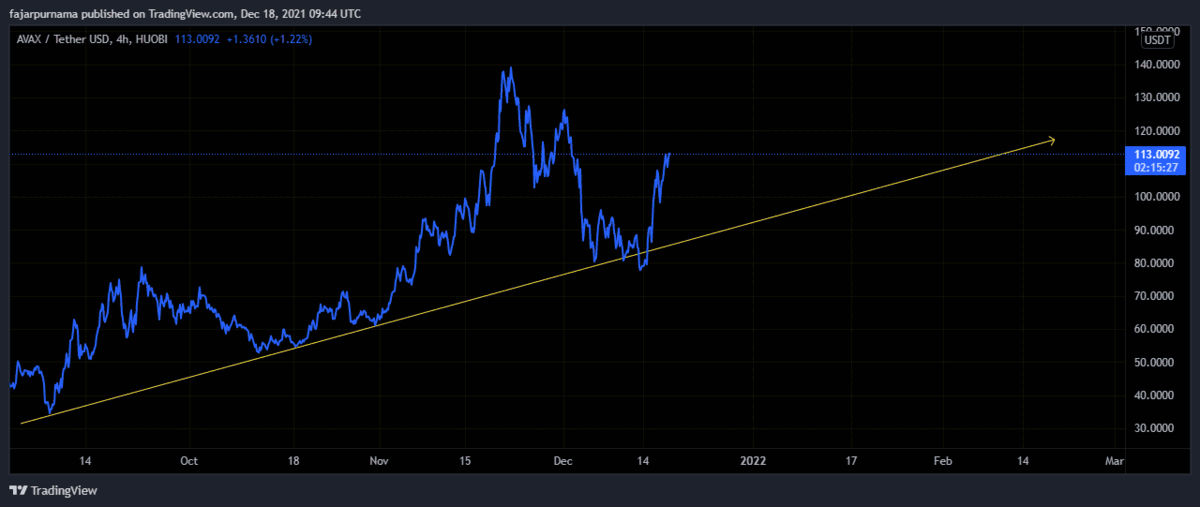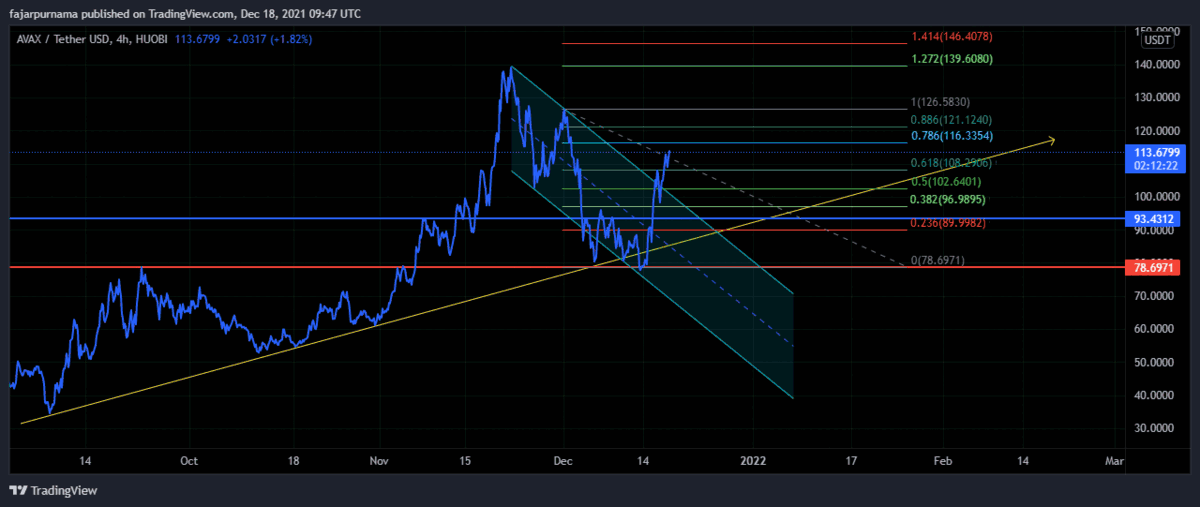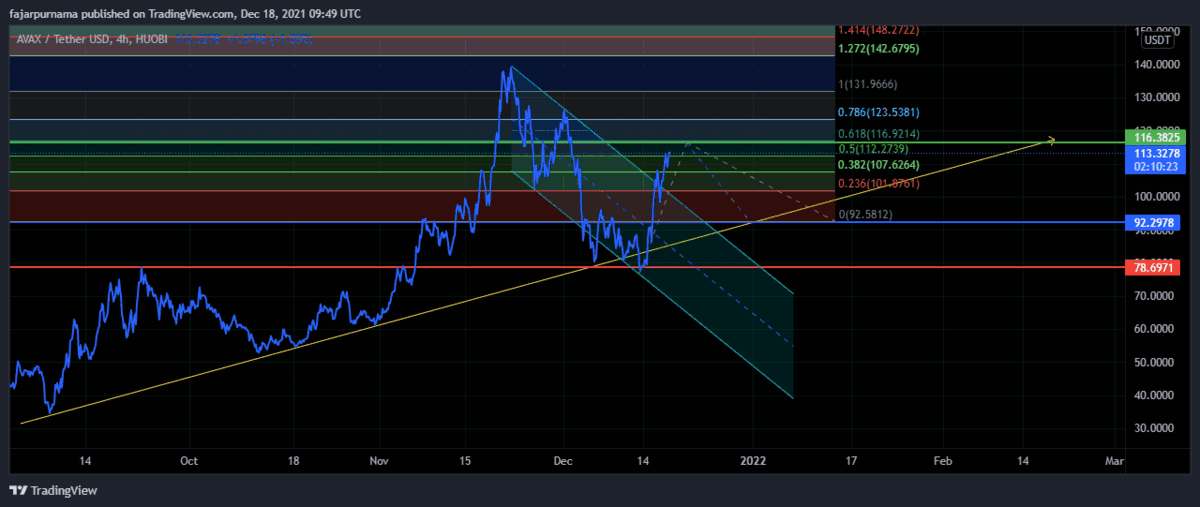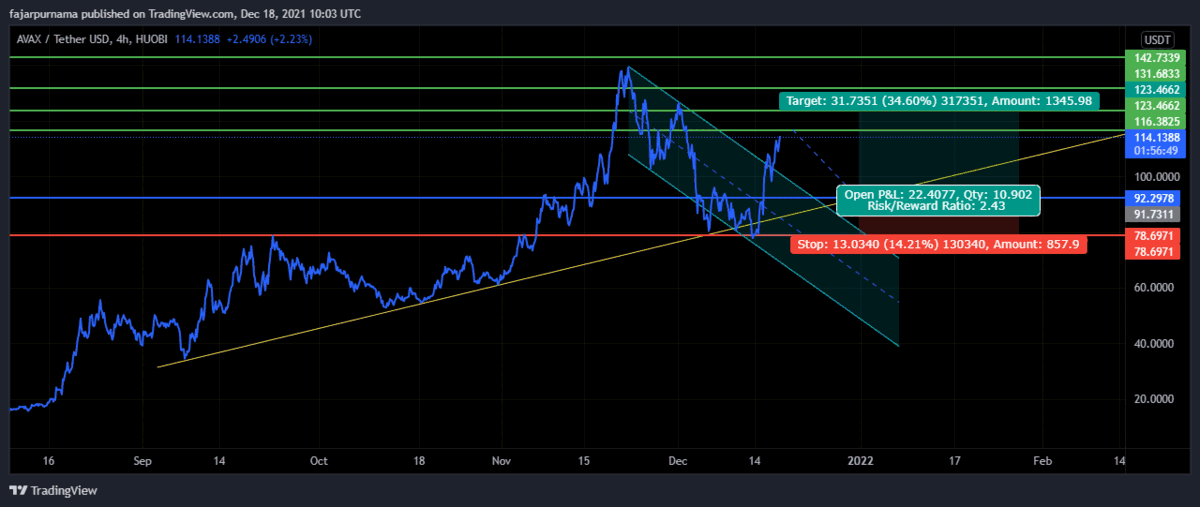
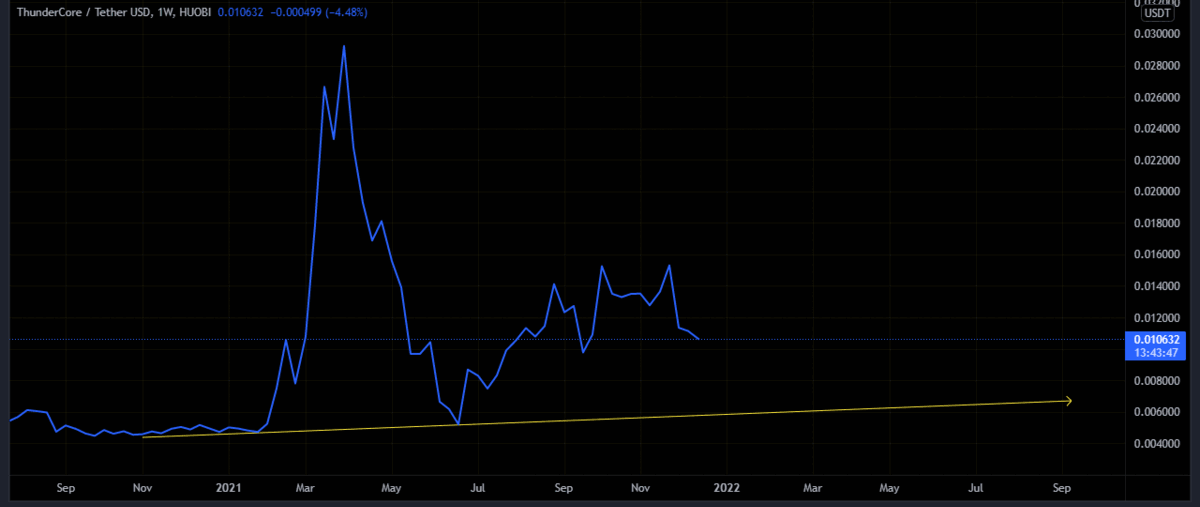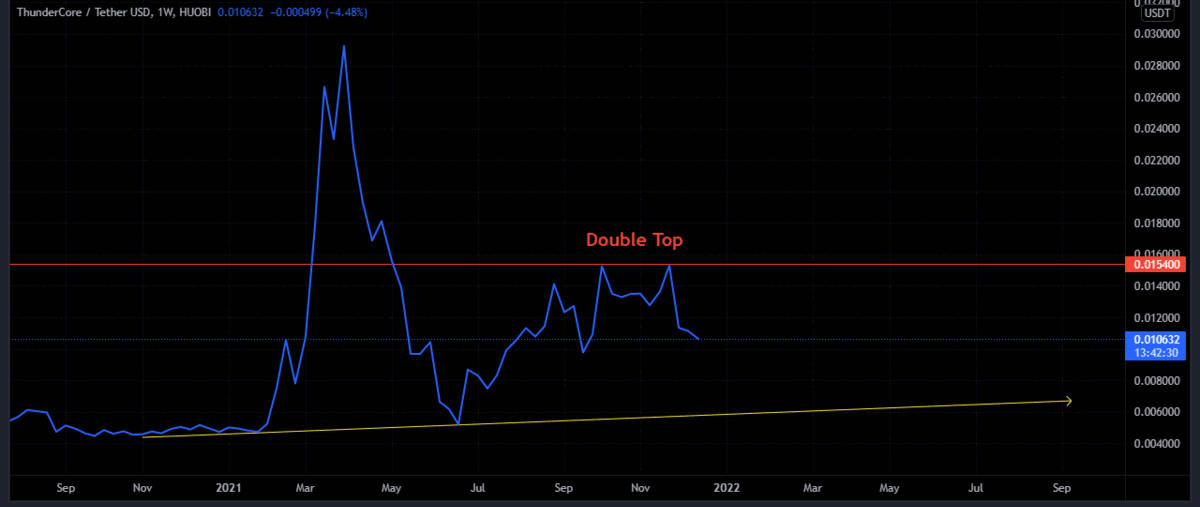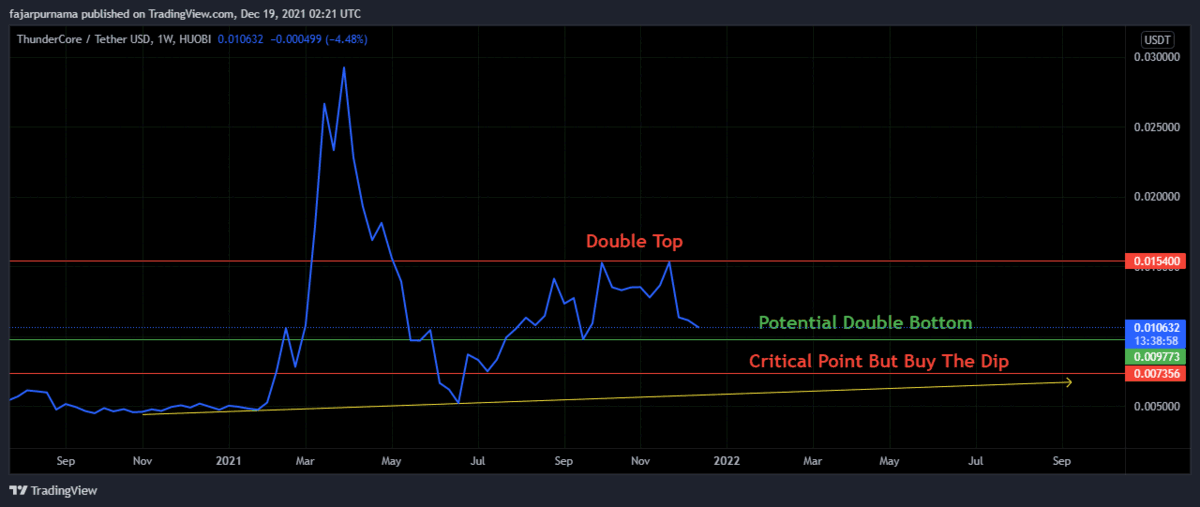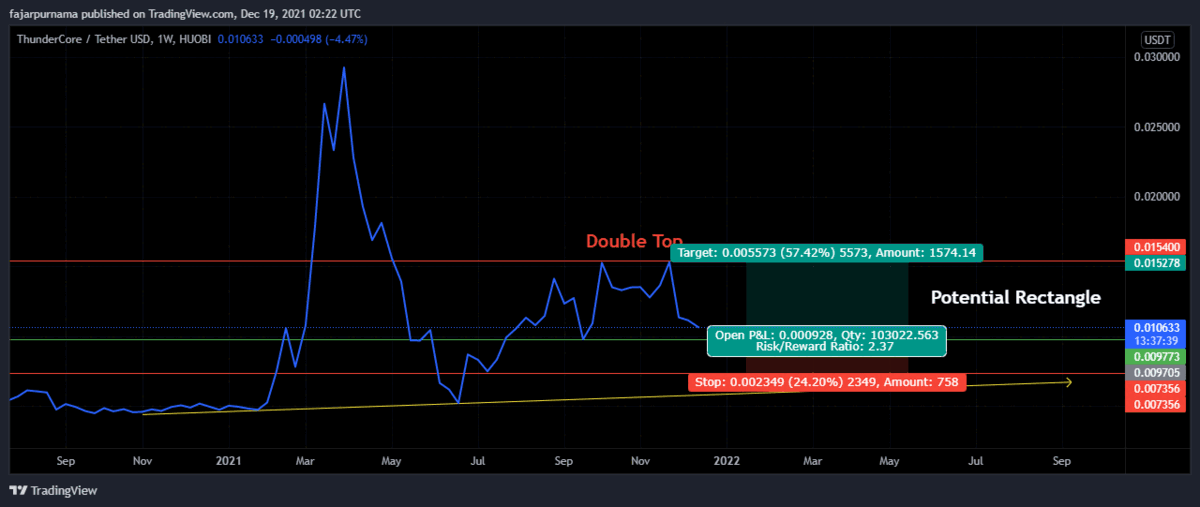
Example Technical Analysis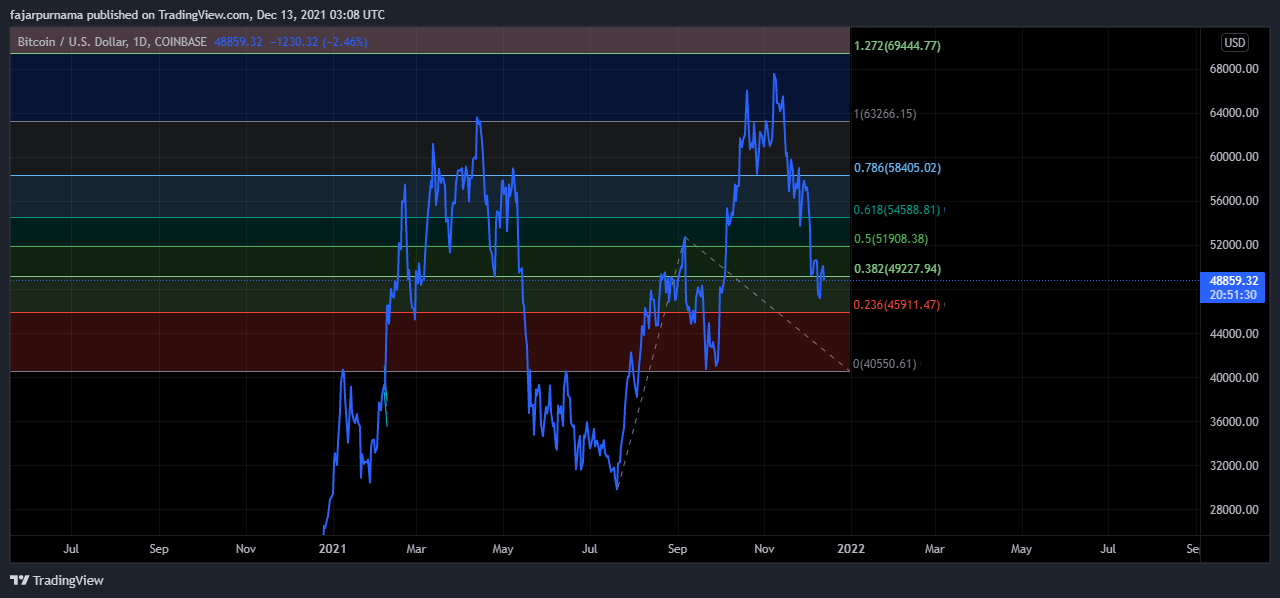
Disclaimer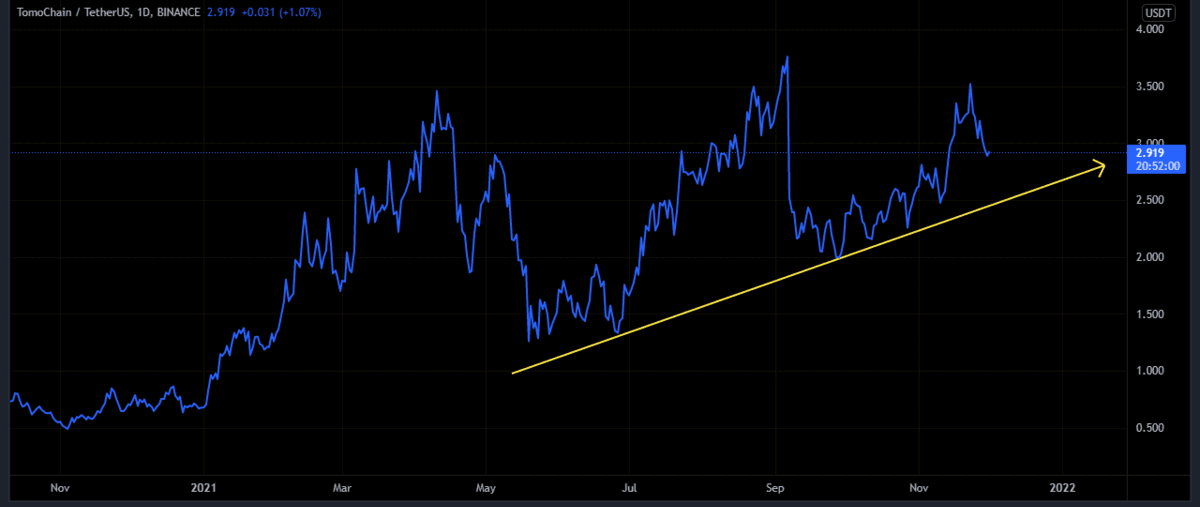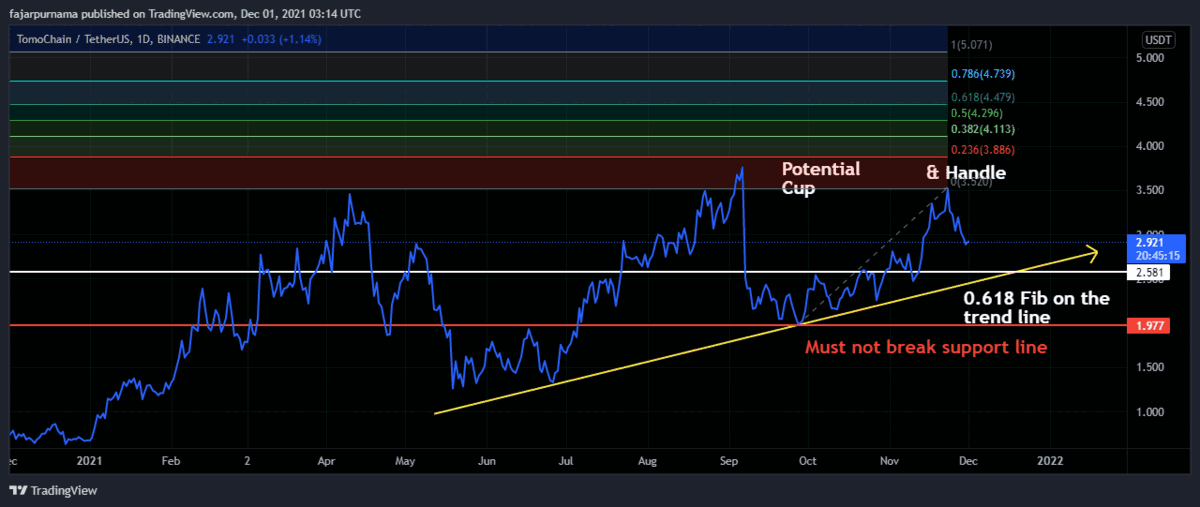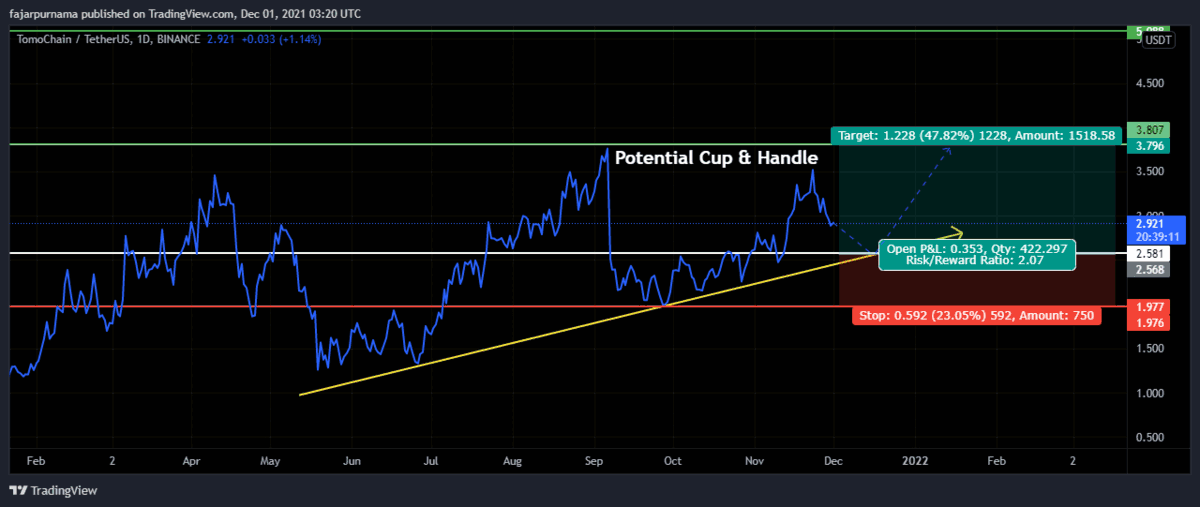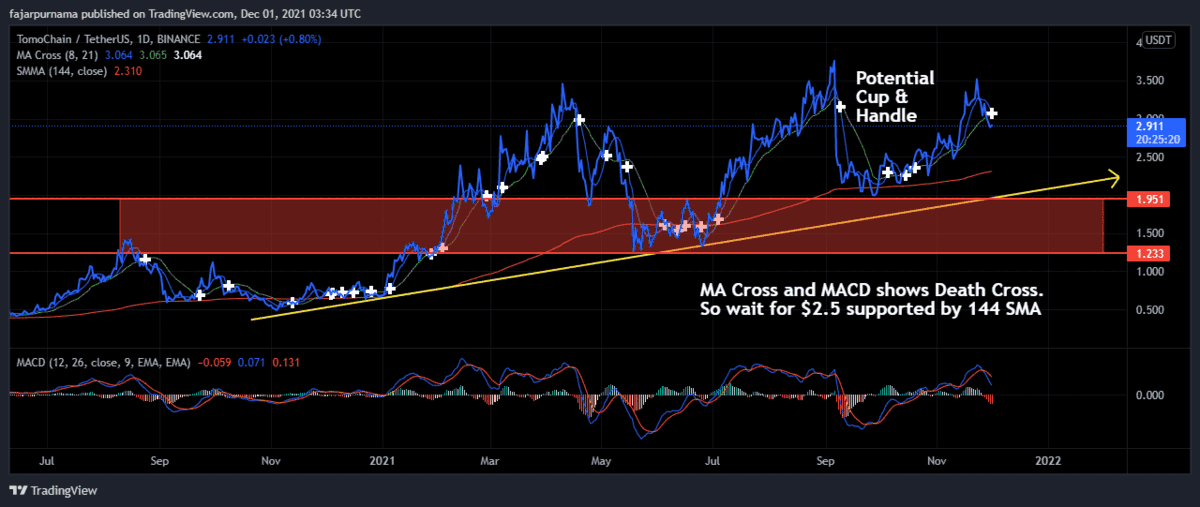
Mirrors
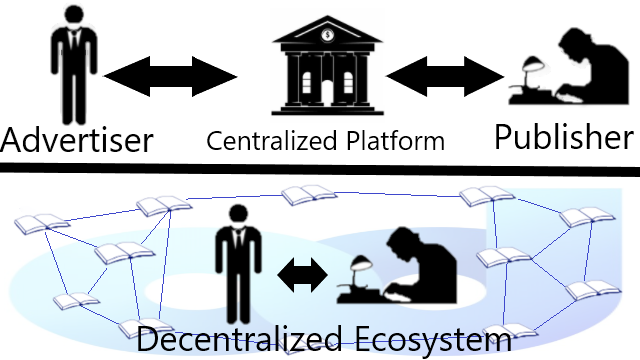
Less Technicals: Joining an Adshare Server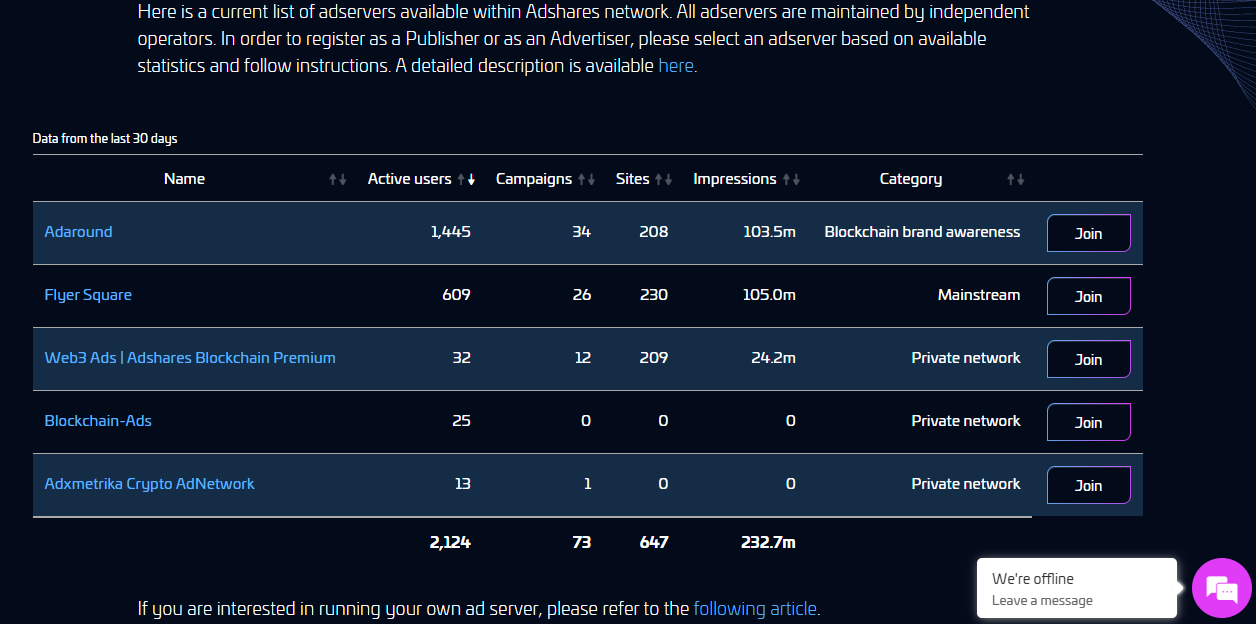
Join as Publishers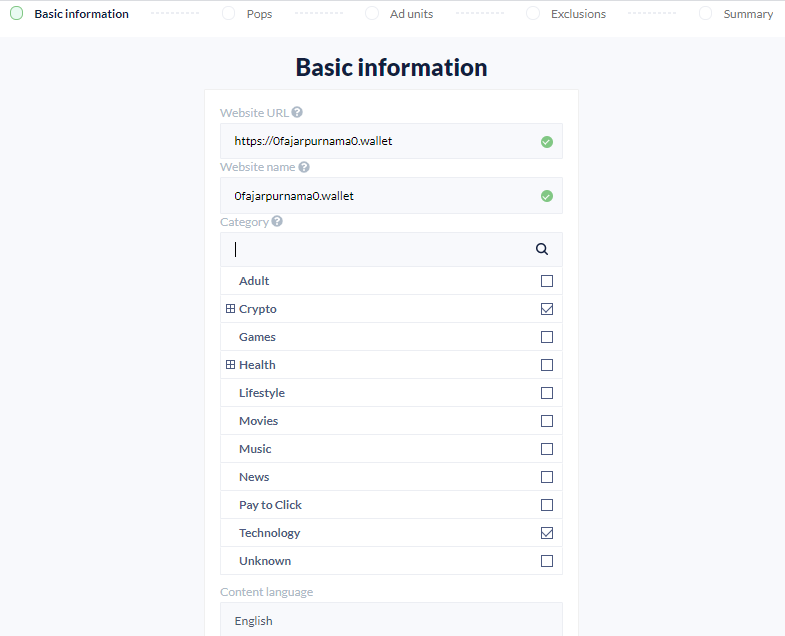
Buy ADS Native Asset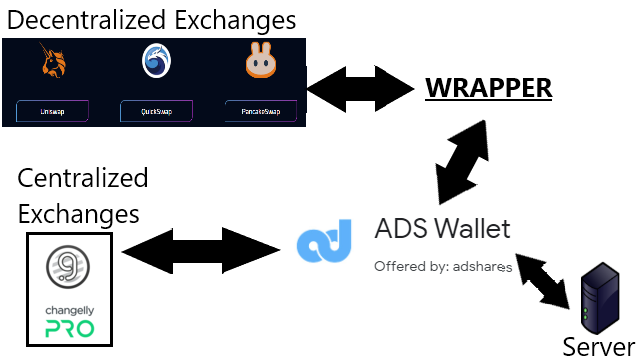
Join as Advertisers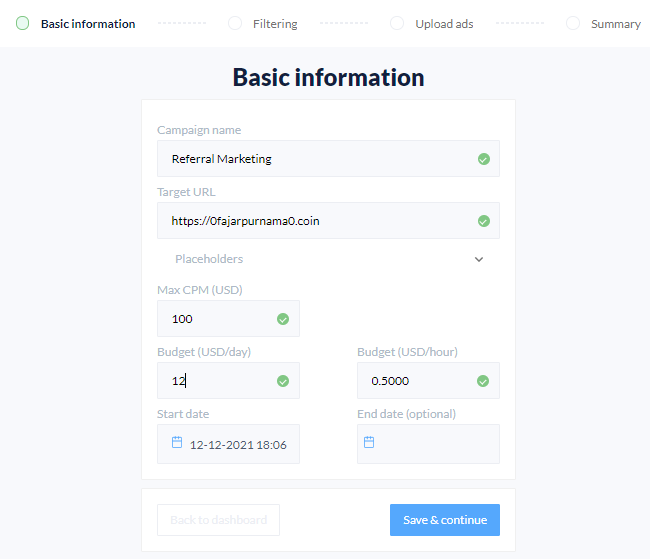
More Technicals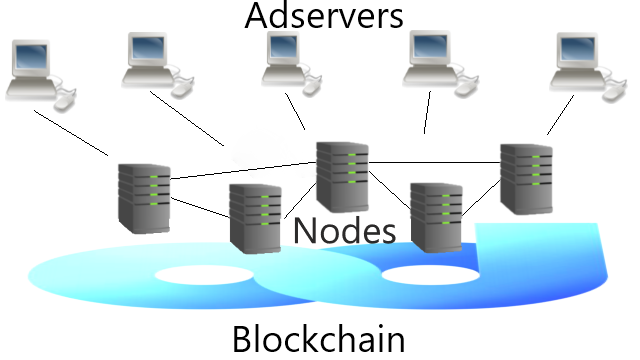
Running The BlockchainAdshare has its own blockchain which is based on Enterprise Service Chain. They have a package called "ads" and "ads-tools" which can be installed and compiled from a repository or we can clone from their github and compile ourselves. Anyway, this is about trying the tools to interact with their blockchain or run a blockchain yourself if you are interested. Running an Adshare NodeAfter installing the blockchain tools, we can start running a node. The blockchain is based on "delegated proof of stake" after all where we can get Dividends as token holders and running master nodes. Nodes on the blockchain is to validate transactions, store the ledger or data, and maintain the consensus. Some operations have fees, so do check the tables. Next is to try the blockchain operator and its panel. Detailed installation are available on their Wiki. Running an Adshare ServerAlthough existing Adservers are more fair than any centralized advertisement platforms, they are still a 3rd party platform similar to Adsense. They can be customized depends on the owner. Therefore, if we are not satisfied with existing Adservers, we can run our own server. We Need Analytic Tools: Open For Anyone To Develop
Mirrors
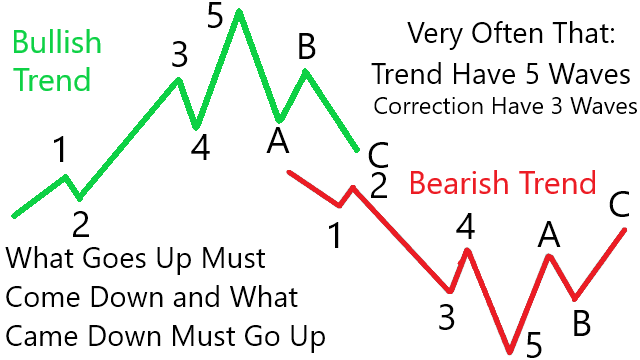
Point Summaries of Elliot Wave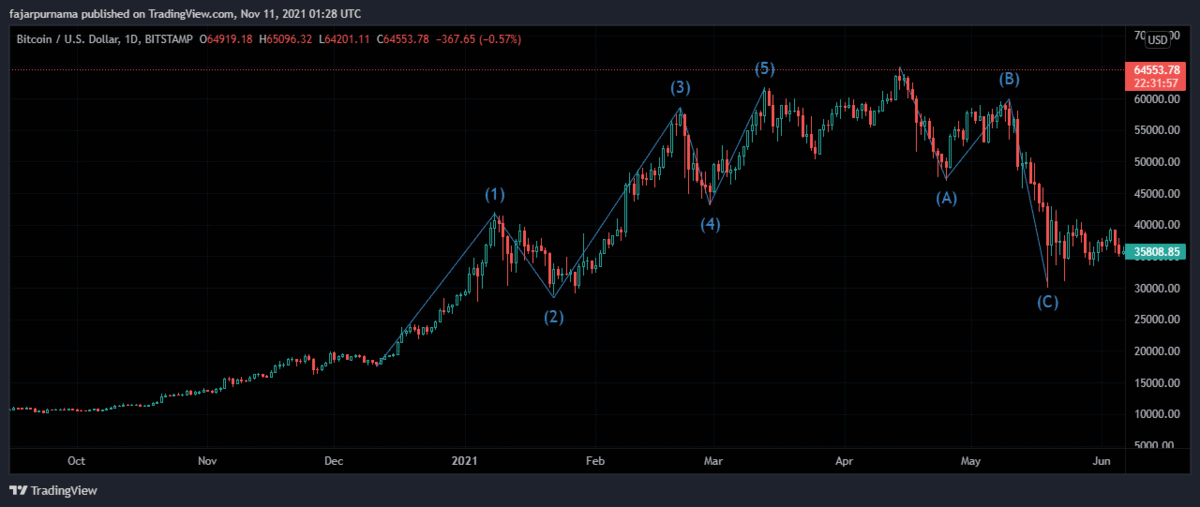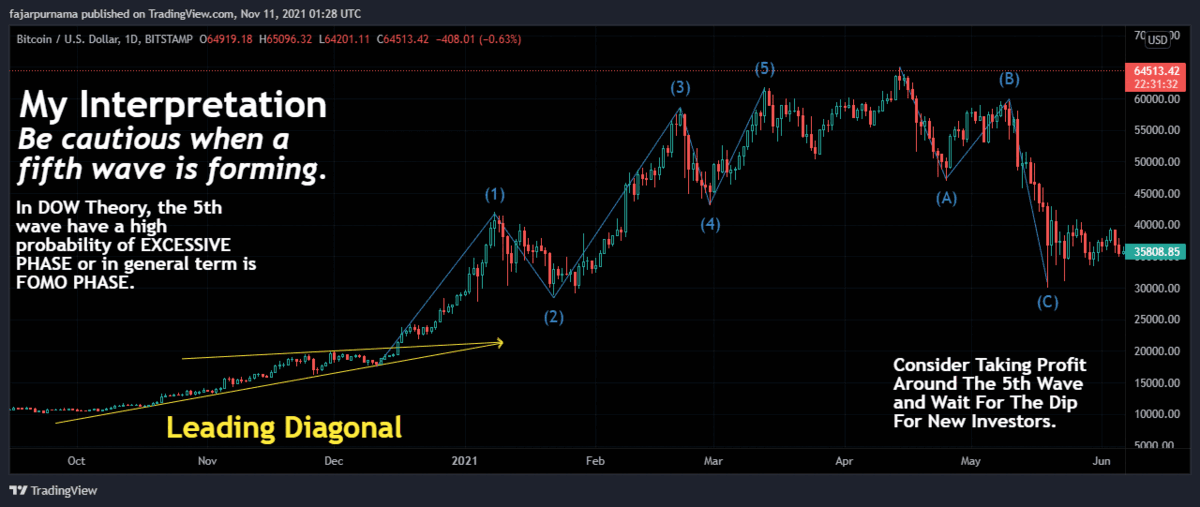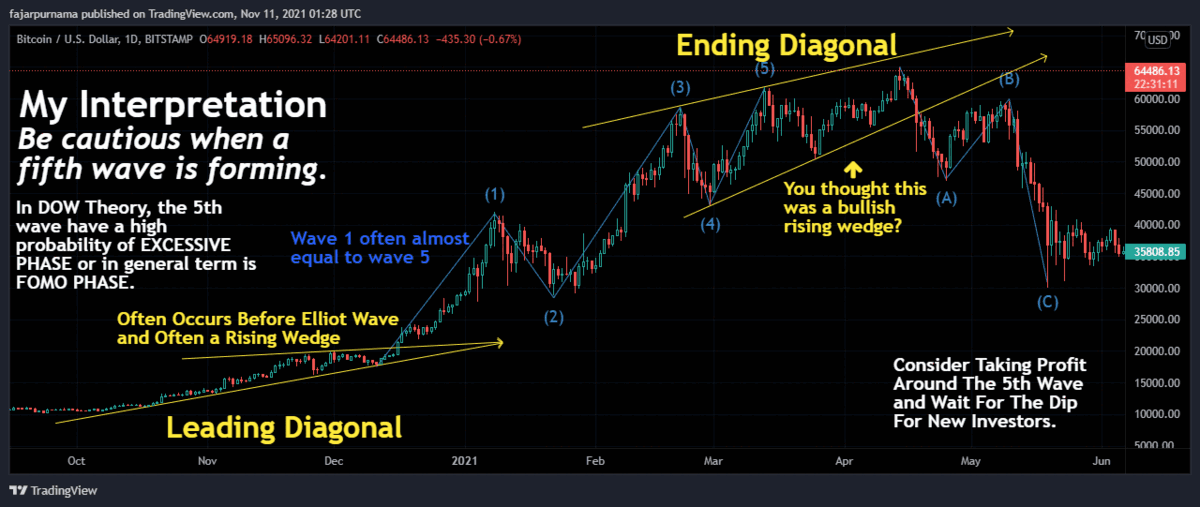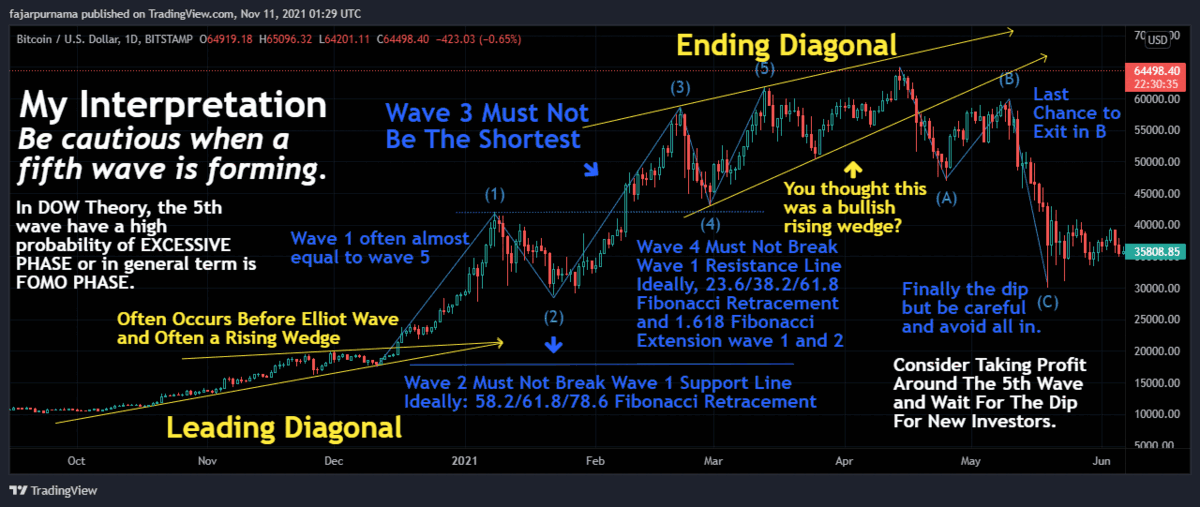
Special Swings Consideration in Low Market Caps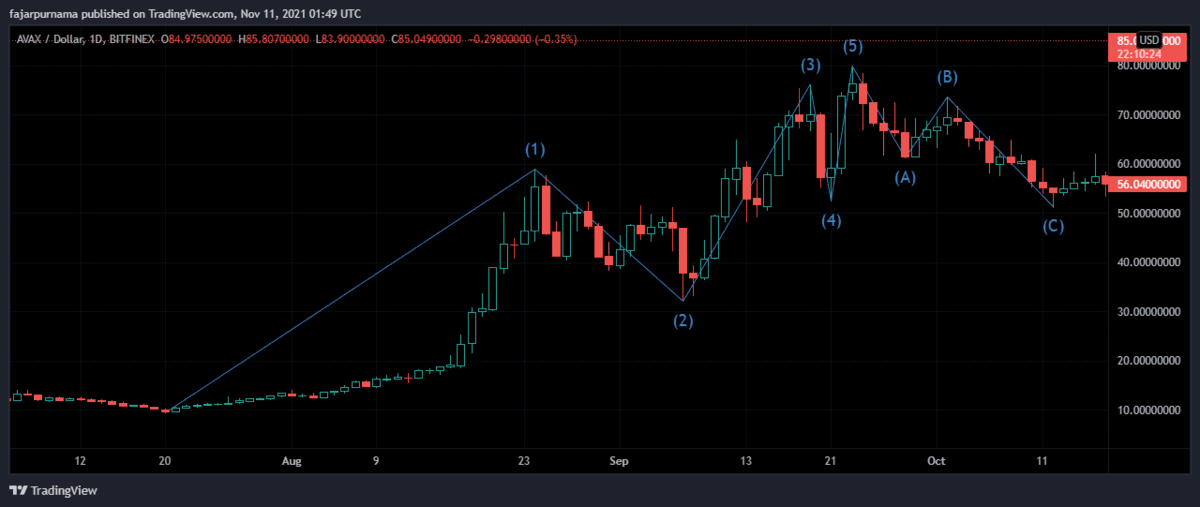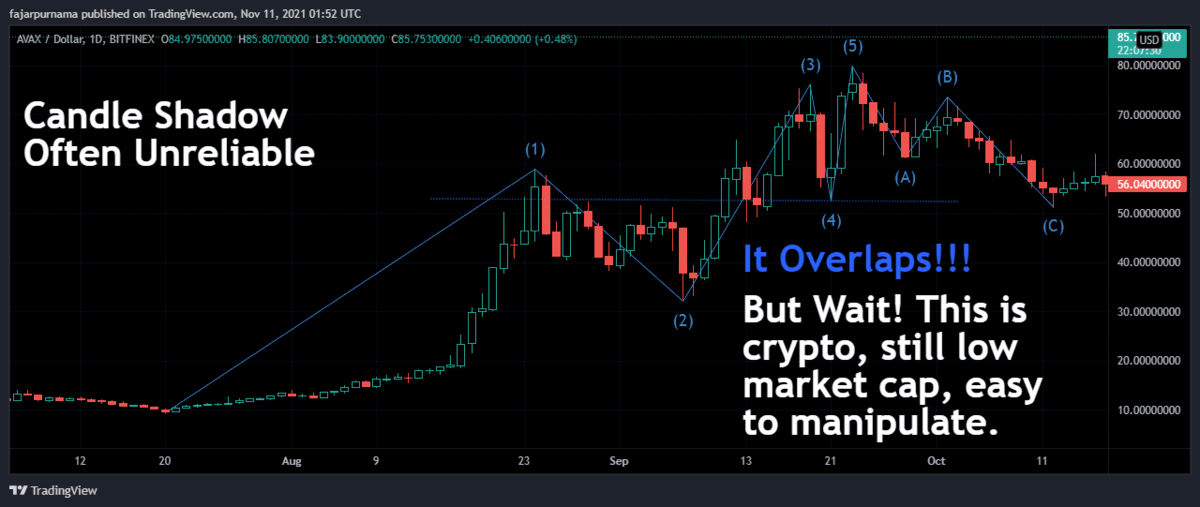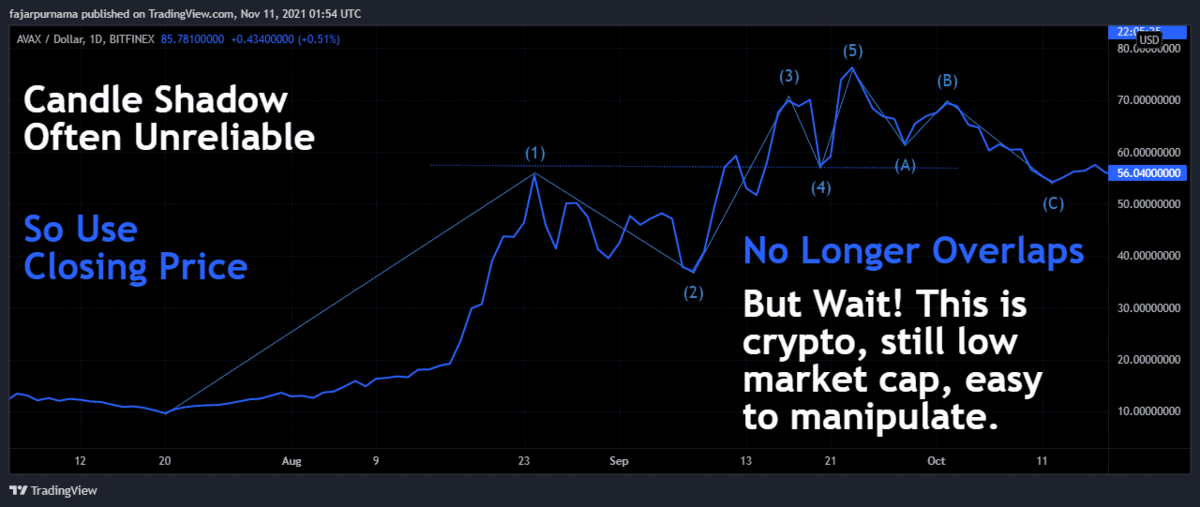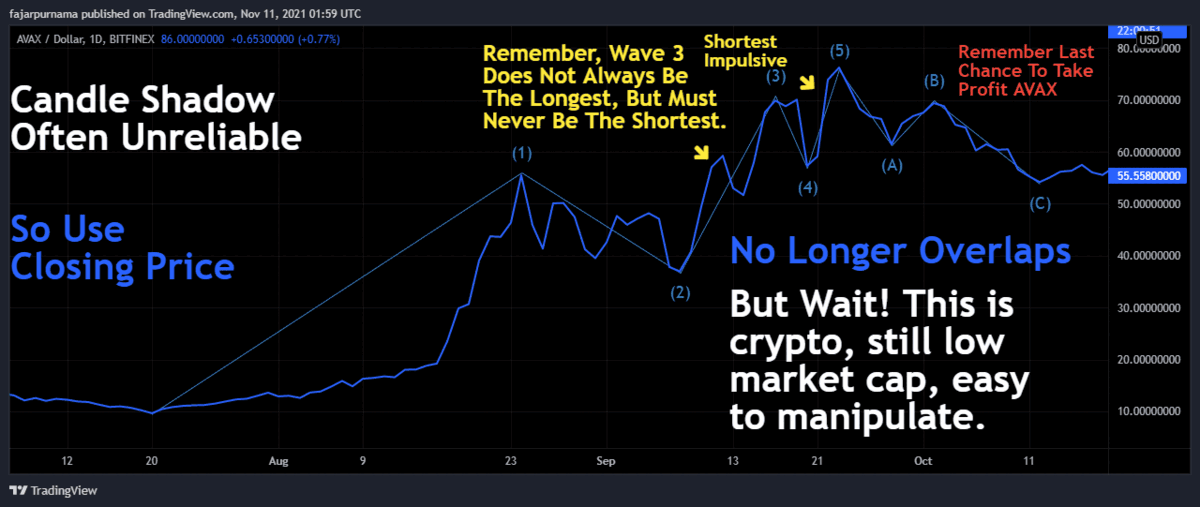
Time Frame Degrees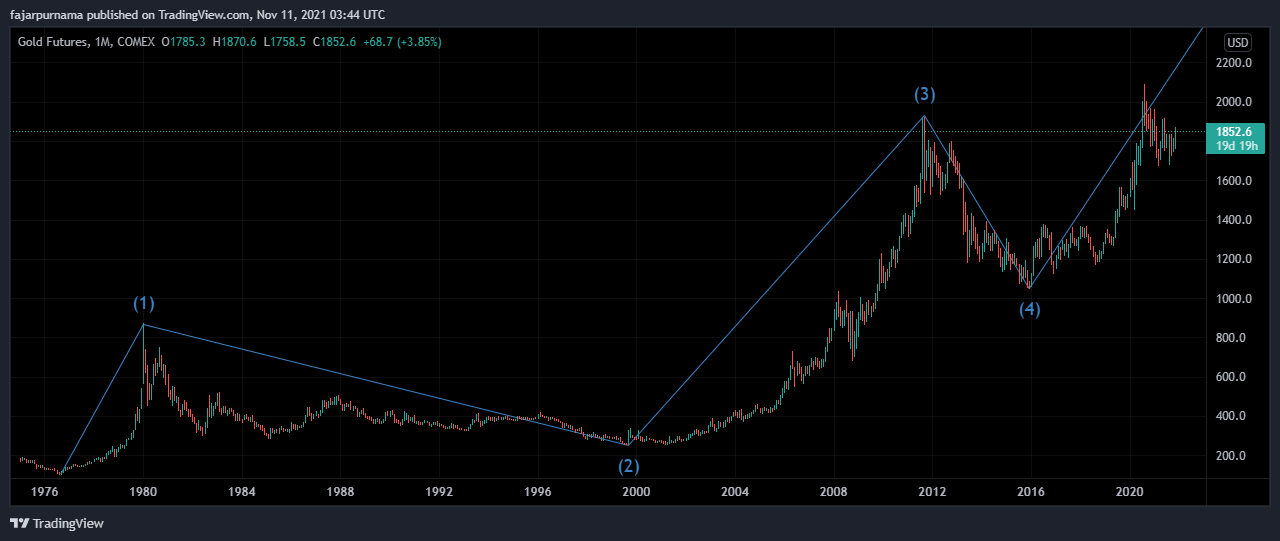
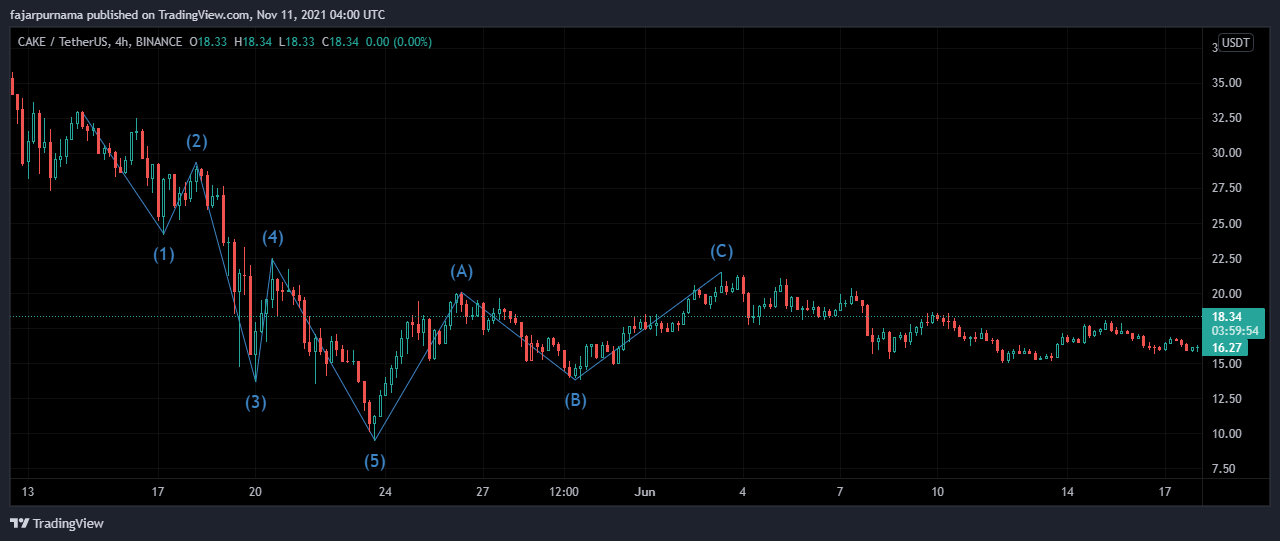
Mirrors
 Berapa Saya Dibayar?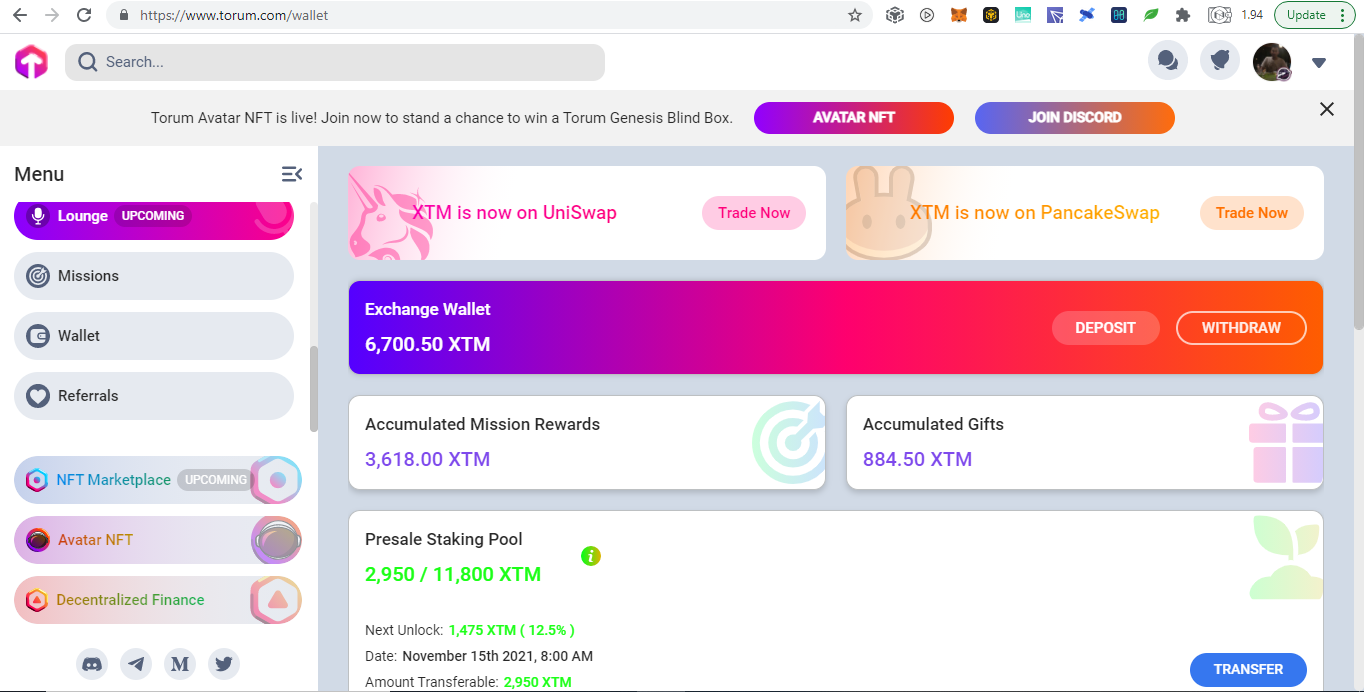 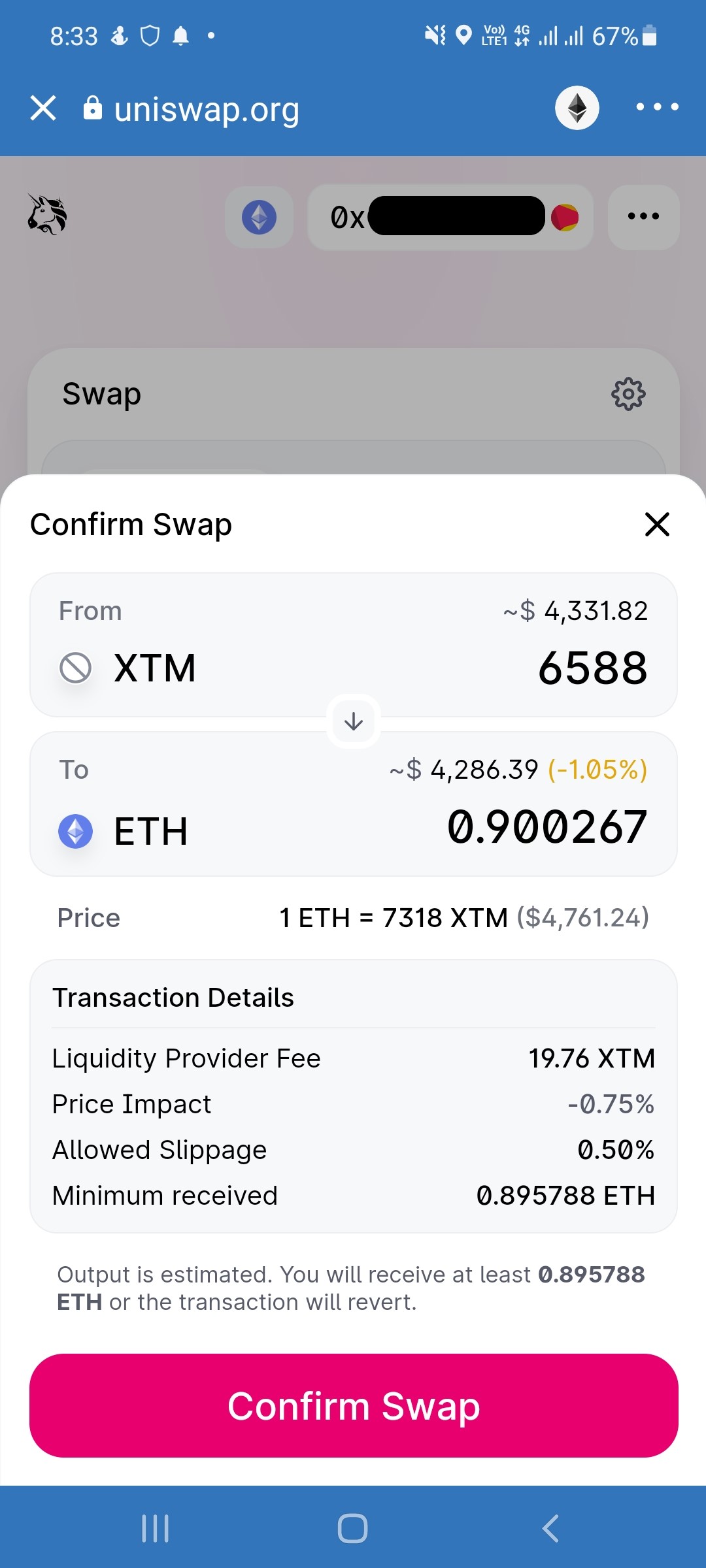 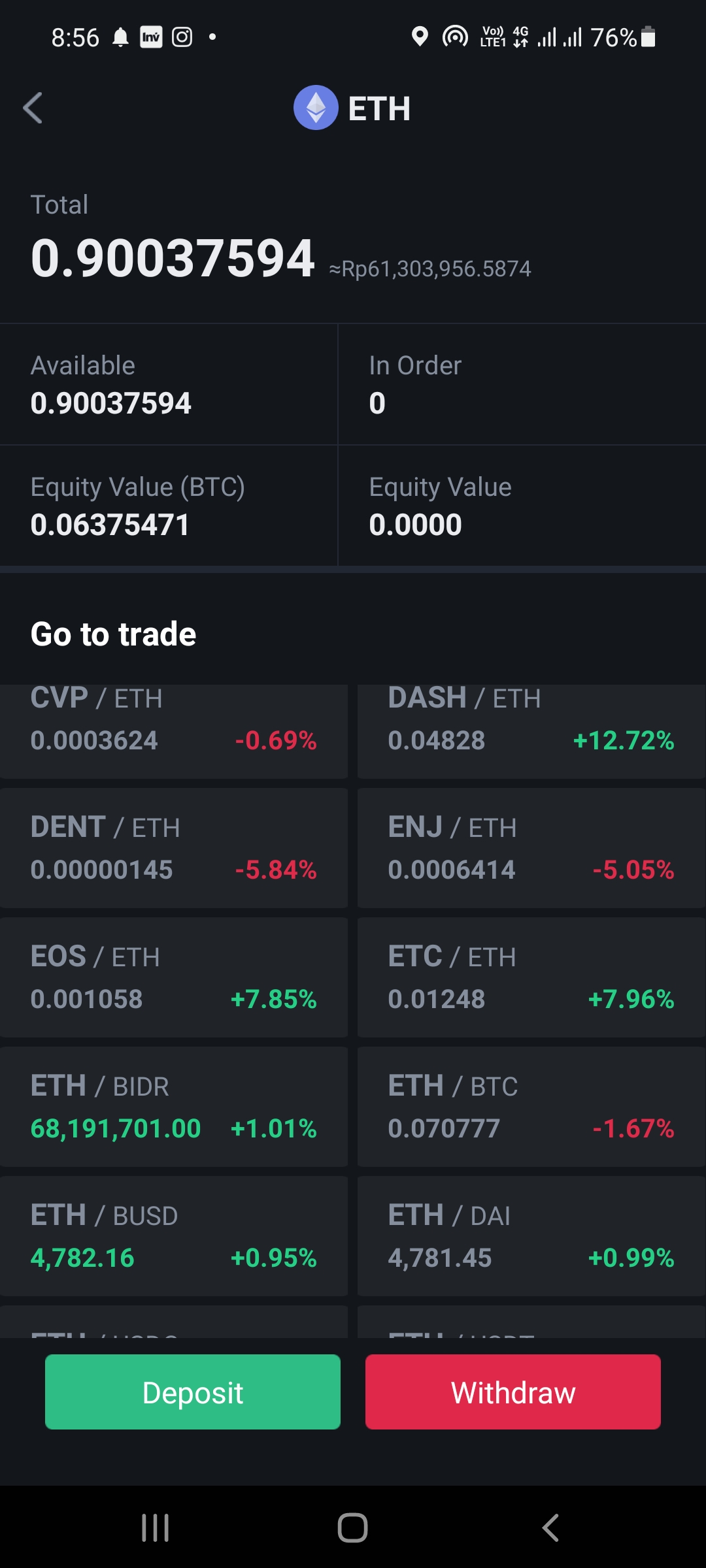 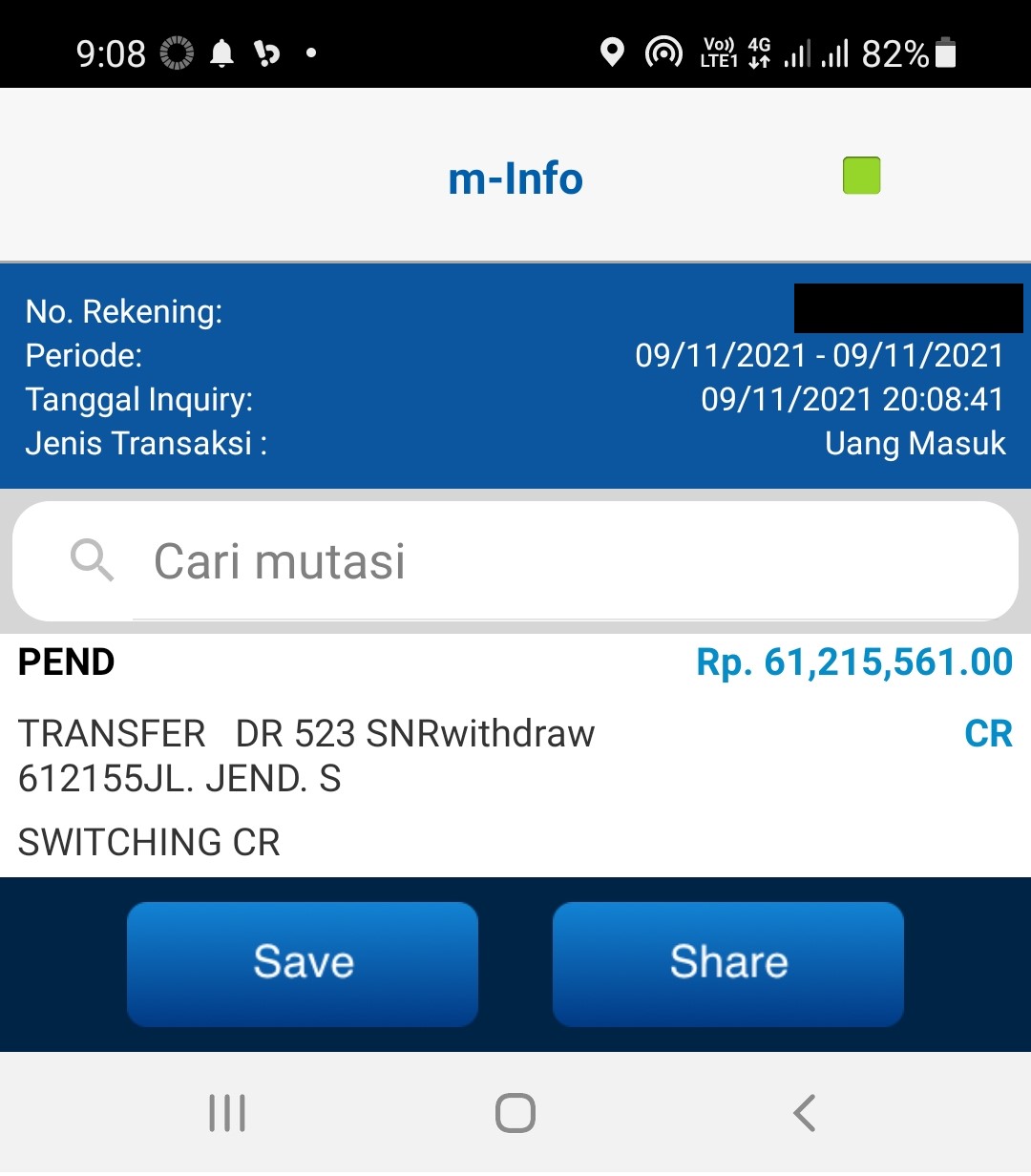 Apa Tugas Saya?
            Apakah Saya Mengkhianati Mereka karena Narik Uang?
This is the first time I heard about "Marhaba DeFi", a DeFi ecosystem that aims to be Shariah compliance. There are many religions in this World, for example in the west there are mostly Christians, in Asia there are Buddhism and Hinduism, and in the middle east there are Jews and Islam. Shariah is the legal practice derived from the teachings of Islamic religion based on its holy book "Quran" and the Prophets and its Muslim people way of life "Hadith". Unless you have many Muslim communities in your area, you probably do not know that there are Muslims who refuse to use banking services because some of them believed to be unlawful practice based on the Islamic teachings. In my country Indonesia, more Shariah Banks are emerging which is different from the traditional banks. The difference is that they abide by the Shariah Law which is believed by many Muslims that they are lawful banks. Then it is not strange to find some Muslims reject most DeFi ecosystem just like they reject the traditional banks because they are not Shariah compliance. This may result in DeFi to never receive some Muslim customers. "Marhaba DeFi" envision on bringing a “Muslim also” platform. "Marhaba" in Arabic means “Welcome”, to welcome not only Muslim users but everyone else as well. General Information in DeFi
For users who are new in DeFi space especially those who are new in the crypto space as whole may not be able to distinguish the uniqueness offered by "Marhaba DeFi". When I read their Lite Paper and White Paper, I found many information that are not exclusive to Shariah practice but general to the whole DeFi space. Cryptocurrency and the rest of its technology are "neutral" as they are only financial technologies (FinTech). It is how they are used what matters to people. Just like how the Internet is neutral, it is what contents inside the Internet that matters. Therefore, I will list them here for you to know so that you can focus in the most important things and avoid embarrassing yourself for being amazed in things that are actually common:
Major Shariah Compliance Believes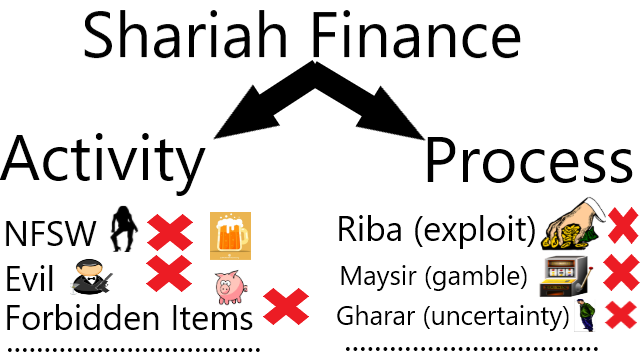
DeFi is only a technology which is neutral. Next is how people use this technology. Out of all the lengthy description by Marhaba DeFi ends in one final question. Is their usage of DeFi Shariah compliance? To learn their concept about Shariah is to read their Shariah Concept Paper and to evaluate, we need to reference from the Quran and Hadith. I think it is too much for average people like us to absorb all those information. Instead, I will just pass on the words of many Muslims I met regarding why they refused to use banking.
If there are no Shariah banks in their regions, some Muslims decides not to use banking at all. Why do some Muslims only uses Shariah banks? Because Shariah banks have full intention to be Shariah compliance which is the same as bearing most of the responsibility of its customers. If at some points Shariah banks commit unlawful practice, the customers will almost not be held responsible because they did all they can to make sure the banks they are using are Shariah compliance. The same goes to financial service providers in DeFi, some Muslims are afraid that they will be held accountable for using services that may potentially involves unlawful activities. Therefore, Marhaba DeFi aims to be a financial service provider in DeFi to be Shariah compliance. Just that declaration will bring confidence in many Muslims to use their services. Upcoming Products Worth MentioningAll non custodial technologies are just technologies which are neutral. For example, a non custodial wallet does not need to be Shariah compliance because they function just like our personal wallet in our pocket and not being held by a bank or exchange to be used for their businesses. However, the marketplace and their financial activities do need to be Shariah compliance:
DisclaimerThe information I wrote above are less facts but more to opinions of Muslim people I heard from. The correct information will always be in the "Quran" and "Hadith". However, my argument is still valid because in business, the truth actually does not matter and what matters is the believes of the people. If Muslims believes them to be unlawful even if they are actually okay after detailed review of the "Quran" and "Hadith", they will stay away from it. Also, not all Muslims are the same, I met many Muslims with different level of strictness, for example there are those who totally avoids alcohol, those who are okay with alcohol to some degree such as being used as medicines, and those who are okay drinking alcohol as long they do not get drunk. Finally, this article is originally Published on https://www.publish0x.com/0fajarpurnama0/do-you-know-that-some-muslims-view-banks-and-defi-as-unlawfu-xwwmvyv?a=4oeEw0Yb0B&tid=publish0xcontest to enter the #MRHBDeFiExplained Writing Contest. How Much Was My Payment?What Was My Job?
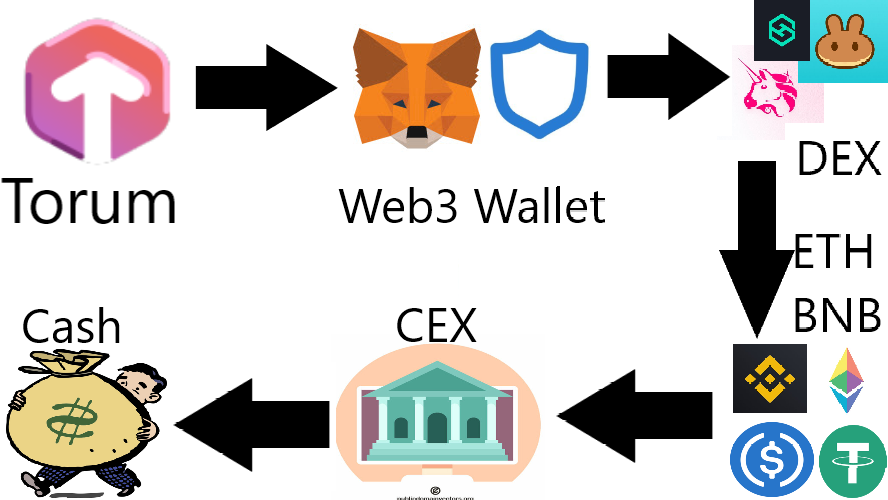
Did I Betray Them for Cashing Out?
Mirrors
|
Archives
August 2022
Categories
All
source code
old source code Get any amount of 0FP0EXP tokens to stop automatic JavaScript Mining or get 10 0FP0EXP tokens to remove this completely. get 30 0FP0EXP Token to remove this paypal donation. get 20 0FP0EXP Token to remove my personal ADS. Get 50 0FP0EXP Token to remove my NFTS advertisements! |
 RSS Feed
RSS Feed

