
1. Cyber Attacks Can Come From Based on This Lecture
Most famous attack is buffer overflow. PCs for file sharing are susceptible to remote buffer overflow. What happens if vulnerability is announced
The first case automatically or manually apply the patch. The second case disable the application or port that is vulnerable. Vulnerability can be:
In case of design, the service must be disabled and reprogram. Case of misconfiguration, edit the configuration file, and as for modules disable and edit the module. To handle the vulnerabilities above the following common steps are taking.
If not taking the steps above then there's a risked in rebuilding the system from the scratch since there's a chance in breaking the system when performing modification. 2. International Standard Organization Information Security ManagementAs written on the first part if it is already infected by a virus or worm then the infection must be cleaned. A software called antivirus had been developed which detects the infection based on patterns of the virus. By installing this software it can prevent and also clean the infections, but even this software is not perfect. If the antivirus cannot detect the infection then it's suggested to take the 5 steps above in dealing with the vulnerability. Worst case we must backup the data, destroy and rebuild the system. The term “policy” is a set of rules and procedures that is agreed by involving parties, and then carried out. In my opinion the strategy build this information security policy must be carried out not in a hasty pace, because it includes parties that is not professional in IT and some are less aware of the cyber attacks that occurs. Even as a information security professional, if given a large book of the information security policy will respond as “this will take time to review”. So it is recommend to take it step by step as in some standards from International Standard Organization (ISO).
0 Comments

1. Kernel Vulnerabilities
2. Server Program and CGI Vulnerabilities
3. Common Steps For Handling Previous Vulnerabilities
If not taking the steps above then there's a risked in rebuilding the system from the scratch since there's a chance in breaking the system when performing modification. 4. Some of My Comments and ExperiencesMy comment is that information security policy becomes necessary at the era of where we live know. As my first experience working at a corporation called Toshiba Tec, informations are very crucial. Just leaking a bit information outside the company can greatly damage both its image and income. There are informations that are highly classified that only the top management have authorization to access. Informations can be in form of physical substance (paper for example), but mostly today in form of electronics (word processor, spread sheet, image, video), that it is forbidden the use of hard drive on the companies private computer. With today's technology it is not unusual that access and exchanges of electronic information relies on computer networks. In my company those in the information system division are responsible in handling the technology of electronic exchange at the same time the privacy of the exchange that informations must not leak outside of the company. They create a set of information security rule that was approved by the top managements of the company (a policy was created). To defend against outside threats, firewall, intrusion detection system, and antivirus were implemented. The networks were also strictly configure of who have the authentication to access. The division is also responsible to protect from the inside whether to prevent information leakage or to prevent information damage. In the policy is stated that employees are forbidden the use of outside electronic devices to connect to the network. A strict monitoring is installed on the IT infrastructure to record the time, and the person who access the information. Also the division is responsible in socializing the information security policy, especially of what both employers and employees are allowed to do and not do. 
1. Mitigation
2. Evasion
3. Treatment
4. Last Resort

1. Network Consists of Clients and Servers
2. There Are Many Bots on The Network
3. Popular Hacking Methods
4. My Prior Knowledge About Penetration Testing

0. NoteThis is the fifth assignment from my Masters Applied Digital Information Theory Course which has never been published anywhere and I, as the author and copyright holder, license this assignment customized CC-BY-SA where anyone can share, copy, republish, and sell on condition to state my name as the author and notify that the original and open version available here. 1. IntroductionThe previous 4th assignment demonstrate 1 bit error detection using 3,4 parity codes. On this assignment will be demonstrating 1 bit error correction using 7,4 hamming codes. On 3,4 parity codes we group 3 bits per block and perform exclusive or on each blocks to get a bit called the parity code bit and add it into the 4th bit of the blocks. A different approach for the 7,4 hamming codes we first group 4 bits per block, and then obtain the 3 hamming bit codes from the 4 bits for each blocks and add them which makes each blocks contained 7 bits. Suppose there are 4 bits as follows: b1,b2,b3,b4 To get the hamming bit codes we do the following calculation: b5=b1⊕b2⊕b3, b6=b1⊕b2⊕b4, b7=b1⊕b3⊕b4 Those bits will be added to the block: b1,b2,b3,b4,b5,b6,b7 Following Table 1 are the complete list: Table 1. Coding Table
On the receiver side the hamming codes is also constructed using the received first 4 bits of each blocks, then compare them with the hamming codes produced on the receiver side. Since the hamming codes were produced using the above equation (each codes uses different elements) we can know on which bit the error occurs, and a correction is performed. For example if receiver's b5, b6, b7 is different from transmitter's then an error on b1, if b5, b6 is different then an error occur on b2, if b5,b7 is different then an error occur on b3, if b6, b7 then b4, if b5 only then b5, if b6 only then b6, if b7 only then b7. Following Table 2 are the complete syndromes: Table 2. Syndrome and Correction List
2. Memoryless Errors (Skew Tent Map)On this simulation we will (1) generate a chaotic binary sequence from memoryless source (2) perform hamming coding (3) simulate through a noisy channel (4) perform error correction on receiver. We will calculate the practical probabilities of incorrect decoding and compare them theoretically defined by PI=1–PC where PC=7p(1-p)6 + (1-p)7 is the probability of correct decoding. The formula is derived from the probability of 1 bit error out of all possible error. Also we will compare the error probability of the binary sequence before correction and after correction. We will use critical point of c=0.499999 for generating the memoryless source, while we use c=1-p for generating the error sequence, and initial chaotic value for both is x(1)=0.333333 and various error probability p for the error sequence (noise). Generating the source will be the same as assignment 2, and generating the hamming codes is similar to 4th assignment except we input 3 extra bits in each blocks based on the initial 4 bits, which will make 7 bits. Like the previous assignment we perform exclusive or between the generated memoryless source and the error sequence to obtain the received sequence. On Table 3 is the simulation result of 1000000 (million) blocks (N) (7000000 bits) with error probability up to 0.4. Table 3. simulation result of 1000000 (million) blocks (N) (7000000 bits) with error probability up to 0.4
3. Markov-type Errors (PWL Map)Similar to section 2 but this time we generate the error sequence through Markov type or Piece Wise Linear (PWL) map. The theoretical incorrect error decoding is PI=1–PC and correct one: PC = P(1)p2 (1-p)5 + 5P(0)p1 p2 (1-p1)4 + P(0)(1-p1)5 p1 + P(0)(1-p1)6 We use the same critical point and initial chaotic value. To generate the error sequence we use the PWL map with various p2 values and P1 = (1-c)/c P2, with c=1-p. On Table 4 is the theoretical result of 1000000 (million) blocks (N) (7000000 bits) with error probability up to 0.4, Table 5 is the simulation result, Table 6 is error probability before decoding, Table 7 is error probability after decoding. Table 4. Theoretical Result
Table 5 Simulation Result
Table 6. Error Probability Before Decoding
Table 7. Error Probability After Decoding
4. ResultsOn Figure 1 shows that the error probability before and after decoding fluctuates on different error probability values (p) and type of sources (memoryless and p2s), but had one thing in common that belowp < 0.3 the error after decoding decreases, and unfortunately rises above that. The incorrect coding for memoryless is preferable when p < 0.1 but not recommended when above. For PWL with p2=0.1 shows low incorrect decoding amongst other p2. For other values there is a cutting point on p=0.2, below lower p2 shows lower incorrect decoding and viceversa. 

5. Source CodeThe source code is written in Fortran95 which is said to be a good programming language for mathematics in the old days, the first one is for memoryless, and the first one is for PWL (markov). program Memoryless_Error_Hamming ! For safe purposes implicit none ! Type declarations integer :: m, n1, n2, i, j, s1, s2, s3 real :: c, c_error, p, practical_error_before, p_practical_error_before, practical_error_after real :: p_practical_error_after, incorrect_decoding, p_incorrect_decoding real :: p_theory_correct_decoding, p_theory_incorrect_decoding real, dimension(40000000) :: x integer, dimension(40000000) :: bit integer, dimension(70000000) :: bit_hamming, bit_error, bit_receiver, bit_hamming_uncorrected, bit_corrected character(len=20) :: firstname, lastname, text write (*,'(A)',advance='no') 'Enter number of blocks: ' read (*,*) m n1 = m*4 n2 = m*7 c = 0.499999 ! Memoryless Generated Source (here n is number of bits) x(1) = 0.333333 do i = 1, n1-1 if (x(i) >= 0 .and. x(i) < c) then x(i+1) = x(i)/c bit(i) = 0 else x(i+1) = (1-x(i))/(1-c) bit(i) = 1 end if end do ! Hamming Codes j = 1 do i = 1, n2, 7 bit_hamming(i) = bit(j) bit_hamming(i+1) = bit(j+1) bit_hamming(i+2) = bit(j+2) bit_hamming(i+3) = bit(j+3) bit_hamming(i+4) = xor(xor(bit(j),bit(j+1)),bit(j+2)) bit_hamming(i+5) = xor(xor(bit(j),bit(j+1)),bit(j+3)) bit_hamming(i+6) = xor(xor(bit(j+1),bit(j+2)),bit(j+3)) j = j+4 end do ! Error Sequence write (*,'(A)',advance='no') 'Enter error probability: ' read (*,*) p c_error = 1 - p do i = 1, n2 if (x(i) >= 0 .and. x(i) < c_error) then x(i+1) = x(i)/c_error bit_error(i) = 0 else x(i+1) = (1-x(i))/(1-c_error) bit_error(i) = 1 end if end do ! Receiver Side (hamming encoded sequence + error sequence), calculate error probability before decoding, prefill future corrected bits practical_error_before = 0; do i = 1, n2 bit_receiver(i) = xor(bit_hamming(i), bit_error(i)) bit_corrected(i) = bit_receiver(i) if (bit_receiver(i) /= bit_hamming(i)) then practical_error_before = practical_error_before + 1 end if end do p_practical_error_before = practical_error_before/n2 ! Perform Hamming coding again on the received bits do i = 1, n2, 7 bit_hamming_uncorrected(i) = bit_receiver(i) bit_hamming_uncorrected(i+1) = bit_receiver(i+1) bit_hamming_uncorrected(i+2) = bit_receiver(i+2) bit_hamming_uncorrected(i+3) = bit_receiver(i+3) bit_hamming_uncorrected(i+4) = xor(xor(bit_receiver(i),bit_receiver(i+1)),bit_receiver(i+2)) bit_hamming_uncorrected(i+5) = xor(xor(bit_receiver(i),bit_receiver(i+1)),bit_receiver(i+3)) bit_hamming_uncorrected(i+6) = xor(xor(bit_receiver(i+1),bit_receiver(i+2)),bit_receiver(i+3)) end do ! Error Correction based on symptoms, "&" is placed to continue next line (fortran95 cannot read long lines) do i = 1, n2, 7 if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i) = xor(bit_receiver(i),1) else if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) == bit_receiver(i+6))) then bit_corrected(i+1) = xor(bit_receiver(i+1),1) else if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) == bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i+2) = xor(bit_receiver(i+2),1) else if ((bit_hamming_uncorrected(i+4) == bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i+3) = xor(bit_receiver(i+3),1) else if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) == bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) == bit_receiver(i+6))) then bit_corrected(i+4) = xor(bit_receiver(i+4),1) else if ((bit_hamming_uncorrected(i+4) == bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) == bit_receiver(i+6))) then bit_corrected(i+5) = xor(bit_receiver(i+5),1) else if ((bit_hamming_uncorrected(i+4) == bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) == bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i+6) = xor(bit_receiver(i+6),1) end if end do ! Error Probability After Decoding practical_error_after = 0; do i = 1, n2 if (bit_corrected(i) /= bit_hamming(i)) then practical_error_after = practical_error_after + 1 end if end do p_practical_error_after = practical_error_after/n2 ! Probability of Correct, and incorrect decoding p_theory_correct_decoding = (7*p*(1-p)*(1-p)*(1-p)*(1-p)*(1-p)*(1-p))+((1-p)*(1-p)*(1-p)*(1-p)*(1-p)*(1-p)*(1-p)) p_theory_incorrect_decoding = 1 - p_theory_correct_decoding incorrect_decoding = 0 do i = 1, n2, 7 if ((bit_corrected(i) /= bit_hamming(i)) .or. (bit_corrected(i+1) /= bit_hamming(i+1)) .or. & (bit_corrected(i+2) /= bit_hamming(i+2)) .or. (bit_corrected(i+3) /= bit_hamming(i+3)) .or. & (bit_corrected(i+4) /= bit_hamming(i+4)) .or. (bit_corrected(i+5) /= bit_hamming(i+5)) .or. & (bit_corrected(i+6) /= bit_hamming(i+6))) then incorrect_decoding = incorrect_decoding + 1 end if end do p_incorrect_decoding = incorrect_decoding/m ! Results write (*,'(A)',advance='no') 'Practical error before decoding: ' write (*,*) practical_error_before write (*,'(A)',advance='no') 'Practical error after decoding: ' write (*,*) practical_error_after write (*,'(A)',advance='no') 'Probability practical error before decoding: ' write (*,*) p_practical_error_before write (*,'(A)',advance='no') 'Probability practical error after decoding: ' write (*,*) p_practical_error_after write (*,'(A)',advance='no') 'Incorrect decoding: ' write (*,*) incorrect_decoding write (*,'(A)',advance='no') 'Probability of incorrect decoding: ' write (*,*) p_incorrect_decoding write (*,'(A)',advance='no') 'Theoretical probability of incorrect decoding: ' write (*,*) p_theory_incorrect_decoding ! Debugging purposes, uncomment them to see binary sequences, max 18 blocks ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_hamming(i) ! end do ! write (*,*) ' ' ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_error(i) ! end do ! write (*,*) ' ' ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_receiver(i) ! end do ! write (*,*) ' ' ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_corrected(i) ! end do ! write (*,*) ' ' end program Memoryless_Error_Hamming program Piece_Wise_Linear_Error ! For safe purposes implicit none ! Type declarations integer :: m, n1, n2, i, j, s1, s2, s3 real :: c, c_error, p, practical_error_before, p_practical_error_before, practical_error_after real :: p_practical_error_after, incorrect_decoding, p_incorrect_decoding real :: p_theory_correct_decoding, p_theory_incorrect_decoding real :: p1, p2, a, a1, a2, a3, c1, c2, d1, d2 real, dimension(40000000) :: x integer, dimension(40000000) :: bit integer, dimension(70000000) :: bit_hamming, bit_error, bit_receiver, bit_hamming_uncorrected, bit_corrected character(len=20) :: firstname, lastname, text write (*,'(A)',advance='no') 'Enter number of blocks: ' read (*,*) m n1 = m*4 n2 = m*7 c = 0.499999 x(1) = 0.333333 ! Uncomment to use memoryless source ! Memoryless Generated Source (here n is number of bits) ! x(1) = 0.333333 ! do i = 1, n1-1 ! if (x(i) >= 0 .and. x(i) < c) then ! x(i+1) = x(i)/c ! bit(i) = 0 ! else ! x(i+1) = (1-x(i))/(1-c) ! bit(i) = 1 ! end if ! end do ! PWL Generated Source p1 = (1-c)*p2/c a = 1/(1-(p1+p2)) if (p1+p2 < 1) then c1 = c-(c/a) c2 = c+((1-c)/a) d1 = c1*(1-c) d2 = 1-((1-c2)*c) a1 = -c/(c1-d1) a2 = a a3 = (c-1)/(d2-c2) do i = 1, n2 if (x(i) >= 0 .and. x(i) < c1) then x(i+1) = (a1*(x(i)-d1))+c else if (x(i) >= c1 .and. x(i) < c2) then x(i+1) = a2*(x(i)-c1) else x(i+1) = (a3*(x(i)-c2))+1 end if if (x(i) >= 0 .and. x(i) < c) then bit(i) = 0 else bit(i) = 1 end if end do else c1 = c-((c-1)/a) c2 = c-(c/a) d1 = c1*(1-c) d2 = 1-((1-c2)*(1-c)) a1 = -c/(c1-d1) a2 = a a3 = c/(d2-c2) do i = 1, n2 if (x(i) >= 0 .and. x(i) < c1) then x(i+1) = (a1*(x(i)-d1))+c else if (x(i) >= c1 .and. x(i) < c2) then x(i+1) = (a2*(x(i)-c1))+1 else x(i+1) = a3*(x(i)-c2) end if if (x(i) >= 0 .and. x(i) < c) then bit(i) = 0 else bit(i) = 1 end if end do end if ! Hamming Codes j = 1 do i = 1, n2, 7 bit_hamming(i) = bit(j) bit_hamming(i+1) = bit(j+1) bit_hamming(i+2) = bit(j+2) bit_hamming(i+3) = bit(j+3) bit_hamming(i+4) = xor(xor(bit(j),bit(j+1)),bit(j+2)) bit_hamming(i+5) = xor(xor(bit(j),bit(j+1)),bit(j+3)) bit_hamming(i+6) = xor(xor(bit(j+1),bit(j+2)),bit(j+3)) j = j+4 end do ! Error Sequence write (*,'(A)',advance='no') 'Enter error probability: ' read (*,*) p c_error = 1 - p write (*,'(A)',advance='no') 'Enter p2: ' read (*,*) p2 p1 = (1-c_error)*p2/c_error a = 1/(1-(p1+p2)) if (p1+p2 < 1) then c1 = c_error-(c_error/a) c2 = c_error+((1-c_error)/a) d1 = c1*(1-c_error) d2 = 1-((1-c2)*c_error) a1 = -c_error/(c1-d1) a2 = a a3 = (c_error-1)/(d2-c2) do i = 1, n2 if (x(i) >= 0 .and. x(i) < c1) then x(i+1) = (a1*(x(i)-d1))+c_error else if (x(i) >= c1 .and. x(i) < c2) then x(i+1) = a2*(x(i)-c1) else x(i+1) = (a3*(x(i)-c2))+1 end if if (x(i) >= 0 .and. x(i) < c_error) then bit_error(i) = 0 else bit_error(i) = 1 end if end do else c1 = c_error-((c_error-1)/a) c2 = c_error-(c_error/a) d1 = c1*(1-c_error) d2 = 1-((1-c2)*(1-c_error)) a1 = -c_error/(c1-d1) a2 = a a3 = c_error/(d2-c2) do i = 1, n2 if (x(i) >= 0 .and. x(i) < c1) then x(i+1) = (a1*(x(i)-d1))+c_error else if (x(i) >= c1 .and. x(i) < c2) then x(i+1) = (a2*(x(i)-c1))+1 else x(i+1) = a3*(x(i)-c2) end if if (x(i) >= 0 .and. x(i) < c_error) then bit_error(i) = 0 else bit_error(i) = 1 end if end do end if ! Receiver Side (hamming encoded sequence + error sequence), calculate error probability before decoding, prefill future corrected bits practical_error_before = 0; do i = 1, n2 bit_receiver(i) = xor(bit_hamming(i), bit_error(i)) bit_corrected(i) = bit_receiver(i) if (bit_receiver(i) /= bit_hamming(i)) then practical_error_before = practical_error_before + 1 end if end do p_practical_error_before = practical_error_before/n2 ! Perform Hamming coding again on the received bits do i = 1, n2, 7 bit_hamming_uncorrected(i) = bit_receiver(i) bit_hamming_uncorrected(i+1) = bit_receiver(i+1) bit_hamming_uncorrected(i+2) = bit_receiver(i+2) bit_hamming_uncorrected(i+3) = bit_receiver(i+3) bit_hamming_uncorrected(i+4) = xor(xor(bit_receiver(i),bit_receiver(i+1)),bit_receiver(i+2)) bit_hamming_uncorrected(i+5) = xor(xor(bit_receiver(i),bit_receiver(i+1)),bit_receiver(i+3)) bit_hamming_uncorrected(i+6) = xor(xor(bit_receiver(i+1),bit_receiver(i+2)),bit_receiver(i+3)) end do ! Error Correction based on symptoms, "&" is placed to continue next line (fortran95 cannot read long lines) do i = 1, n2, 7 if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i) = xor(bit_receiver(i),1) else if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) == bit_receiver(i+6))) then bit_corrected(i+1) = xor(bit_receiver(i+1),1) else if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) == bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i+2) = xor(bit_receiver(i+2),1) else if ((bit_hamming_uncorrected(i+4) == bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i+3) = xor(bit_receiver(i+3),1) else if ((bit_hamming_uncorrected(i+4) /= bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) == bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) == bit_receiver(i+6))) then bit_corrected(i+4) = xor(bit_receiver(i+4),1) else if ((bit_hamming_uncorrected(i+4) == bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) /= bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) == bit_receiver(i+6))) then bit_corrected(i+5) = xor(bit_receiver(i+5),1) else if ((bit_hamming_uncorrected(i+4) == bit_receiver(i+4)) .and. (bit_hamming_uncorrected(i+5) == bit_receiver(i+5)) & .and. (bit_hamming_uncorrected(i+6) /= bit_receiver(i+6))) then bit_corrected(i+6) = xor(bit_receiver(i+6),1) end if end do ! Error Probability After Decoding practical_error_after = 0; do i = 1, n2 if (bit_corrected(i) /= bit_hamming(i)) then practical_error_after = practical_error_after + 1 end if end do p_practical_error_after = practical_error_after/n2 ! Probability of Correct, and incorrect decoding p_theory_correct_decoding = (((1-c_error)*p2*((1-p1)**5)) + (5*c_error*p1*p2*((1-p1)**4)) + (c_error*((1-p1)**5)*p1) + & (c_error*((1-p1)**6))) p_theory_incorrect_decoding = 1 - p_theory_correct_decoding incorrect_decoding = 0 do i = 1, n2, 7 if ((bit_corrected(i) /= bit_hamming(i)) .or. (bit_corrected(i+1) /= bit_hamming(i+1)) .or. & (bit_corrected(i+2) /= bit_hamming(i+2)) .or. (bit_corrected(i+3) /= bit_hamming(i+3)) .or. & (bit_corrected(i+4) /= bit_hamming(i+4)) .or. (bit_corrected(i+5) /= bit_hamming(i+5)) .or. & (bit_corrected(i+6) /= bit_hamming(i+6))) then incorrect_decoding = incorrect_decoding + 1 end if end do p_incorrect_decoding = incorrect_decoding/m ! Results write (*,'(A)',advance='no') 'Practical error before decoding: ' write (*,*) practical_error_before write (*,'(A)',advance='no') 'Practical error after decoding: ' write (*,*) practical_error_after write (*,'(A)',advance='no') 'Probability practical error before decoding: ' write (*,*) p_practical_error_before write (*,'(A)',advance='no') 'Probability practical error after decoding: ' write (*,*) p_practical_error_after write (*,'(A)',advance='no') 'Incorrect decoding: ' write (*,*) incorrect_decoding write (*,'(A)',advance='no') 'Probability of incorrect decoding: ' write (*,*) p_incorrect_decoding write (*,'(A)',advance='no') 'Theoretical probability of incorrect decoding: ' write (*,*) p_theory_incorrect_decoding ! Debugging purposes, uncomment them to see binary sequences, max 18 blocks ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_hamming(i) ! end do ! write (*,*) ' ' ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_error(i) ! end do ! write (*,*) ' ' ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_receiver(i) ! end do ! write (*,*) ' ' ! do i = 1, n2 ! write(*,'(1i1.1)',advance='no') bit_corrected(i) ! end do ! write (*,*) ' ' end program Piece_Wise_Linear_Error 0. NoteThis is the fourth assignment from my Masters Applied Digital Information Theory Course which has never been published anywhere and I, as the author and copyright holder, license this assignment customized CC-BY-SA where anyone can share, copy, republish, and sell on condition to state my name as the author and notify that the original and open version available here. 1. IntroductionOn Figure 1 of Shannon Communication Model, the previous assignments on memoryless and Markov's source is on the first block transmitter (source), while this fourth assignment is on the channel coding and decoding. It will be demonstrated a binary source coded with parity check codes , going through a noisy channel with the specified bit error rate, and decoded on with parity check. On the receiver side will compare the theoretical and practical error using parity check. 
A parity (3,4) check coding takes 3 bits + 1 into 1 block with the last bit as the parity bit obtained by performing exclusive or (xor) on the 3 bits. The blocks are then transmitted and xor is again performed on the decoder side on the 4 bits of the block, and if the result is 0 then it's not regarded as error, but if the result is 1 then it's regarded as error. Looking this checking method it can detect errors when odd numbers of bits error occurs, but it cannot detect when even number of error occurs. This can be demonstrated on the following table. Table 1. Parity Check Examples
2. Skew Tent MapThe binary sequence on the transmitter is generated by means of 2nd assignment of skew tent map with initial x[1] = 0.1 and c = 0.499999. This time we generated in a million blocks with each blocks contains 3 + 1 bits. On the source we generated the initial bits of normal means on assignment 2, but then we slip a parity bit on every 4th increments of the sequence (on the actual code we made 2 sequence where the first sequence as a reference for the sequence with parity bit, b2[0] = b1[0], b2[1] = b1[1], b2[2] = b1[2], b2[3] = b1[0]⊕b1[1]⊕b1[2], b2[4] = b1[3], b2[5] = b1[4], b2[6] = b1[5], b2[7] = b1[3]⊕b1[4]⊕b1[5], and so on). After that we simulate an error sequence with initial x_err[0] = 0.500001, error probability p varies, and c_err = 1-p. Then as per section 1 we xor the parity coded binary sequence with the error simulated generated sequence, obtaining the binary sequence at the receiver. We can find the total errors by comparing the binary sequence on the transmitter side (before xor by error sequence) and on the receiver side (after xor by error sequence). Then we perform xor on each blocks (every 4 bits) of the receiver binary sequence to get the detected error. Finally we calculate the difference between total errors (real) and detected error to find the practical undetected error. The theoretical undetected error can be calculated using the following equation: Pu = 6p2(1-p)2+p4 which is actually a formula of the probability of even blocks after passing through noisy channel with defined error probability. Table 2. Trials of Error Probability to Undetected Error
3. PWL MapRoughly similar to 2nd section but this time use PWL Map error sequence. We start by choosing p2, but generating the error sequence we defined c_err as 1-p (initial c remain 0.499999 and p1 is computed), with p2 still the same, but p1_err is defined based on c_err. Automatically slop a changes and the sequence was generated. The process is the same after that, with the theoretical of undetected error as Pu = P(0)((1-p1)p1(1-p2)+p1(1-p2)p2+p1p2p1) + p(1)(p2(1-p1)p1+p2p1p2+(1-p2)p2(1-p1)+(1-p2)(1-p2)(1-p2)), again is actually a formula of even blocks probability after passing through noisy channel with defined error probability. Table 3. Probability of Practical Undetected Error of different values of p to values of p2
Table 4. Probability of Theoretical Undetected Error of different values of p to values of p2
4. SummaryFrom above the practical value almost matches the theoretical value. As on Figure 2 plotted based on tables above, for error probability below 0.2 the skew tent map has lower undetected error probability which good to use on channels with little noise. For above it's better to use PWL but with p2 value lower than 0.5. 
5. Source CodeThe source code is divided into 2 one for skew tent map and the other for PWL map written in C++. //============================================================================ // Name : skew-tent-map.cpp // Author : Fajar Purnama 152-D8713 // Version : 0.9 // Copyright : Free to distributed with credits to the author. // Description : Source Code for Skew Tent Map in C++ //============================================================================ #include <iostream> using namespace std; int main() { cout << "!!!Hello World!!!" << endl; // prints !!!Hello World!!! int N = 10000*3, bin[N]; float x[N], c = 0.499999; x[0] = 0.3; // N = number of bits (1 block = 3 bits), c = critical point, x[0] = initial value, x[N] = chaotic sequence, and bin[N] = binary sequence // From here is 2nd Assignment for (int i = 0; i < N; ++i){ if (x[i] >= 0 && x[i] < c) { x[i+1] = x[i]/c; bin[i] = 0; } else { x[i+1] = (1-x[i])/(1-c); bin[i] = 1; } } // Insert bit parity on every 4th bit int j = 0, bin_par[N+(N/3)]; for (int i = 0; i < N+(N/3); i += 4){ bin_par[i] = bin[j]; bin_par[i+1] = bin[j+1]; bin_par[i+2] = bin[j+2]; bin_par[i+3] = bin_par[i]^bin_par[i+1]^bin_par[i+2]; j += 3; } // Generate error sequence int bin_err[N+(N/3)]; float p; cout << "Enter error probability: "; cin >> p; float c_err = 1-p, x_err[N+(N/3)]; x_err[0]=0.500001; for (int i = 0; i < N+(N/3); ++i){ if (x_err[i] >= 0 && x_err[i] < c_err) { x_err[i+1] = x_err[i]/c_err; bin_err[i] = 0; } else { x_err[i+1] = (1-x_err[i])/(1-c_err); bin_err[i] = 1; } } // Generate receiver side = parity sequence XOR error sequence int bin_r[N+(N/3)]; for (int i = 0; i < N+(N/3); ++i){ bin_r[i] = bin_par[i] ^ bin_err[i]; } for (int i = 0; i < N+(N/3); ++i){ cout << bin_err[i]; } cout << endl; for (int i = 0; i < N+(N/3); ++i){ cout << bin_par[i]; } cout << endl; for (int i = 0; i < N+(N/3); ++i){ cout << bin_r[i]; } cout << endl << endl; // total error, detected error, undetected error float total_error = 0, detected_error = 0, undetected_error = 0; float p_theory = ((6*p*p)*((1-p)*(1-p))+(p*p*p*p)); for (int i = 0; i < N+(N/3); i += 4){ if((bin_par[i] != bin_r[i])||(bin_par[i+1] != bin_r[i+1])||(bin_par[i+2] != bin_r[i+2])||(bin_par[i+3] != bin_r[i+3])){ ++total_error; } if((bin_r[i]^bin_r[i+1]^bin_r[i+2]^bin_r[i+3])==1){ ++detected_error; } } undetected_error = total_error - detected_error; float p_total_error = total_error/(N/3); float p_detected_error = detected_error/(N/3); float p_undetected_error = undetected_error/(N/3); cout << "total error = " << total_error << endl; cout << "detected error = " << detected_error << endl; cout << endl; cout << "undetected error = " << undetected_error << endl; cout << "probability of total error = " << p_total_error << endl; cout << "probability of detected error = " << p_detected_error << endl; cout << "probability of undetected error = " << p_undetected_error << endl; cout << "theory = " << p_theory << endl; return 0; } //============================================================================ // Name : 43-single-parity-check-codes-large.cpp // Author : Fajar Purnama 152-D8713 // Version : 0.9 // Copyright : Free to distributed with credits to the author. // Description : Source Code for PWL Tent Map in C++ //============================================================================ #include <iostream> using namespace std; int main() { int n; cout << "Enter number of blocks: "; cin >> n; int N = n*3; float p1, p2, c, c1, c2, d1, d2, a, a1, a2, a3; c = 0.499999; cout << "Enter value of p2: "; cin >> p2; p1 = (1-c)*p2/c; a = 1/(1-(p1+p2)); int* bin = new int[N]; // need to do this because int main cannot hold large numbers, a stack overflow occurs so need to allocate to new heap float* x = new float[N]; x[0] = 0.1; // N = number of bits (1 block = 3 bits), c = critical point, x[0] = initial value, x[N] = chaotic sequence, and bin[N] = binary sequence // From here is 3rd Assignment if (p1+p2 < 1){ c1 = c-(c/a); c2 = c+((1-c)/a ); d1 = c1*(1-c); d2 = 1-((1-c2)*c); a1 = -c/(c1-d1); a2 = a; a3 = (c-1)/(d2-c2); for (int i = 0; i < N; ++i){ if (x[i] >= 0 && x[i] < c1) { x[i+1] = (a1*(x[i]-d1))+c; } else if(x[i] >= c1 && x[i] < c2) { x[i+1] = a2*(x[i]-c1); } else { x[i+1] = (a3*(x[i]-c2))+1; } if (x[i] < c){ bin[i] = 0; } else { bin[i] = 1; } } } else if (p1+p2 > 1){ c1 = c-((c-1)/a); c2 = c-(c/a); d1 = c1*(1-c); d2 = 1-((1-c2)*(1-c)); a1 = -c/(c1-d1); a2 = a; a3 = c/(d2-c2); for (int i = 0; i < N; ++i){ if (x[i] >= 0 && x[i] < c1) { x[i+1] = (a1*(x[i]-d1))+c; } else if(x[i] >= c1 && x[i] < c2) { x[i+1] = (a2*(x[i]-c1))+1; } else { x[i+1] = a3*(x[i]-c2); } if (x[i] < c){ bin[i] = 0; } else { bin[i] = 1; } } } else { cout << "you can't do this" << endl; } // Insert bit parity on every 4th bit int j = 0; int* bin_par = new int[N+(N/3)]; for (int i = 0; i < N+(N/3); i += 4){ bin_par[i] = bin[j]; bin_par[i+1] = bin[j+1]; bin_par[i+2] = bin[j+2]; bin_par[i+3] = bin_par[i]^bin_par[i+1]^bin_par[i+2]; j += 3; } // Generate error sequence int* bin_err = new int[N+(N/3)]; float p, p1_err; float* x_err = new float[N+(N/3)]; x_err[0]=x[0]; cout << "Enter error probability :"; cin >> p; float c_err = 1-p; p1_err = (1-c_err)*p2/c_err; a = 1/(1-(p1_err+p2)); if (p1_err+p2 < 1){ c1 = c_err-(c_err/a); c2 = c_err+((1-c_err)/a ); d1 = c1*(1-c_err); d2 = 1-((1-c2)*c_err); a1 = -c_err/(c1-d1); a2 = a; a3 = (c_err-1)/(d2-c2); for (int i = 0; i < N+(N/3); ++i){ if (x_err[i] >= 0 && x_err[i] < c1) { x_err[i+1] = (a1*(x_err[i]-d1))+c_err; } else if(x_err[i] >= c1 && x_err[i] < c2) { x_err[i+1] = a2*(x_err[i]-c1); } else { x_err[i+1] = (a3*(x_err[i]-c2))+1; } if (x_err[i] < c_err){ bin_err[i] = 0; } else { bin_err[i] = 1; } } } else if (p1_err+p2 > 1){ c1 = c_err-((c_err-1)/a); c2 = c_err-(c_err/a); d1 = c1*(1-c_err); d2 = 1-((1-c2)*(1-c_err)); a1 = -c_err/(c1-d1); a2 = a; a3 = c_err/(d2-c2); for (int i = 0; i < N+(N/3); ++i){ if (x_err[i] >= 0 && x_err[i] < c1) { x_err[i+1] = (a1*(x_err[i]-d1))+c_err; } else if(x_err[i] >= c1 && x_err[i] < c2) { x_err[i+1] = (a2*(x_err[i]-c1))+1; } else { x_err[i+1] = a3*(x_err[i]-c2); } if (x_err[i] < c_err){ bin_err[i] = 0; } else { bin_err[i] = 1; } } } else { cout << "you can't do this" << endl; } // Generate receiver side = parity sequence XOR error sequence int* bin_r = new int[N+(N/3)]; for (int i = 0; i < N+(N/3); ++i){ bin_r[i] = bin_par[i] ^ bin_err[i]; } /* Debugging Purpose for (int i = 0; i < N+(N/3); ++i){ cout << bin_err[i]; } cout << endl; for (int i = 0; i < N+(N/3); ++i){ cout << bin_par[i]; } cout << endl; for (int i = 0; i < N+(N/3); ++i){ cout << bin_r[i]; } cout << endl << endl; */ // total error, detected error, undetected error float total_error = 0, detected_error = 0, undetected_error = 0; float p_theory = (c_err*(((1-p1_err)*p1_err*(1-p2))+(p1_err*(1-p2)*p2)+(p1_err*p2*p1_err)))+((1-c_err)*((p2*(1-p1_err)*p1_err)+(p2*p1_err*p2)+((1-p2)*p2*(1-p1_err))+((1-p2)*(1-p2)*(1-p2)))); //float p_theory = (c*(((1-p1)*p1*(1-p2))+(p1*(1-p2)*p2)+(p1*p2*p1)))+((1-c)*((p2*(1-p1)*p1)+(p2*p1*p2)+((1-p2)*p2*(1-p1))+((1-p2)*(1-p2)*(1-p2)))); for (int i = 0; i < N+(N/3); i += 4){ if((bin_par[i] != bin_r[i])||(bin_par[i+1] != bin_r[i+1])||(bin_par[i+2] != bin_r[i+2])||(bin_par[i+3] != bin_r[i+3])){ ++total_error; } if((bin_r[i]^bin_r[i+1]^bin_r[i+2]^bin_r[i+3])==1){ ++detected_error; } } undetected_error = total_error - detected_error; float p_total_error = total_error/(N/3); float p_detected_error = detected_error/(N/3); float p_undetected_error = undetected_error/(N/3); cout << "total error = " << total_error << endl; cout << "detected error = " << detected_error << endl; cout << endl; cout << "undetected error = " << undetected_error << endl; cout << "probability of total error = " << p_total_error << endl; cout << "probability of detected error = " << p_detected_error << endl; cout << "probability of undetected error = " << p_undetected_error << endl; cout << "theory = " << p_theory << endl; return 0; } 0. NoteThis is the third assignment from my Masters Applied Digital Information Theory Course which has never been published anywhere and I, as the author and copyright holder, license this assignment customized CC-BY-SA where anyone can share, copy, republish, and sell on condition to state my name as the author and notify that the original and open version available here. 1. IntroductionOn the first assignment we produced a chaotic sequence based skew tent map by showing that output sequence is uncontrollable as on the chaos theory. A large sequence produced by skew tent map is uniformly distributed. On the second assignment we produce a memoryless binary sequence based on the first assignment's skew tent map based chaotic sequence. The probability of 0, 1, 00, 01, 10, 11, and the Markov chain is analyze. Finally the entropy is calculated based on the critical points of each data and find the correlation between the entropy and expected compression ratio. This time the same method on assignment 2 is used but change the assignment 1 of not using skew tent map but piecewise linear map. 2. Piecewise Linear Chaotic Map
The design procedure of Markov Source we choose 4 values p1, and p2 based on Figure 1. Then can obtain the value c (steady state probability) with the formula c=P(0)=P2/(P1+P2), and then we can find the slope a=1/(1-(p1+p2)). The limitation here is we cannot choose the value that satisfy p1+p2 = 1. We are now ready to design the chaotic map. Basic knowledge on line equation is necessary here the one that refers to the equation y = ax + d where a is the slope that we calculated. There will be 3 lines and at least a positive and negative must be use. Each line we calculate its slope. For Figure 2 we calculate slope a = (y2 – y1)/(x2 – x1). For a=(c-0)/(c-c1)from point x,y of (c1,0) and (c,c). From the equation we can define c1=c-c/a. There's also another slope for a=(1-c)/(c2-c)from point (c,c) and (c2,1) which then we can define c2=c+(1-c)/a. With the first line as negative slope the length proportion of c1:d1 = 1:1-c thus d1 = c1(1-c), and for the third line also negative slope 1-c2:1-d2 = 1:c which we can define d2 = 1+(1-c)c. That's almost all the equation we need, next is to find slope a1 and a2. 

For both figure the method to find a1 and a3 is the same which is by using 2 points (x1,y1) and (x2,y2) with calculation slope = (y2 – y1)/(x2 – x1). We use point (d1,c) and (c1,0) for a1. a1=(0-c)/(c1-d1), as for a3 we use (c2,1) and (d2,c) a3=(c-1)/(d2-c2). Finally we can form each line y1, y2, and y3, using equation y – y1 = a(x – x1), but for the map y is regarded as t (it'll be t = a(x-x1) + y1). We then use the following equation to generate the chaotic sequence of p1+p2 < 1. t = (a1(x-d1))+c for (0⩽x < c1) t = a(x-c1) for (c1⩽x < c2) t= a3(x-c2)+1 for (c2⩽x < 1) For p1+p2 < 1 on the other hand have to change some equation to do the slope a is negative. 

On Figure 3 we change one slope for it to be positive, and here we chose a3. Since the slope a2 changes to negative the equation c1 and c2 changes as well, a = (y2 – y1)/(x2 – x1) a=(c-1)/(c-c1)from point x,y of (c1,1) and (c,c). From the equation we can define c1=c-(c-1)/a. C2 changes as well a=(0-c)/(c2-c) from point (c2,0) and (c,c) which then we can define c2=c-c/a. The slope on a1 is still negative, so no changes for d1, but third line we change to positive slope 1-c2:1-d2 = 1:1-c which we can define d2 = 1-(1-c2)(1-c). The last change is on a3=(c-0)/(d2-dc) using point (c2,0) and (d2,c). Not to forget a changes slop recently so t had to be modified based on t = a(x-x1)+y1, the equation then becomes: t = (a1(x-d1))+c for (0⩽x < c1) t = a(x-c1)+1 for (c1⩽x < c2) t = a3(x-c2) for (c2⩽x < 1) Now we can generate the chaotic sequence on Figure 4. We can see that for p1+p2 < 1 seems more periodic. Lastly on this section we would like to show that the distribution is uniform on Figure 5. 



3. Binary SequencesAfter that we do the same as assignment 2, generating the binary sequences and counting the 0s and 1s. The result below are as the theory where P(0)=c, P(1)=1-c, P(0|0)=1-p1, P(0|1)=p1, P(1|0)=p2, P(1|1)=1-p2, P(00)=P(0|0)*P(0), P(01)=P(0|1)*P(1), P(10)=P(1|0)*P(1), P(11)=P(1|1)*P(1).
We also perform entropy calculation of the generated binary sequence. We chose to compress the file into format “.tar.gz” one of famous compression in Linux, but this time we use the reversed formula of the second assignment for the compression rate CompressionRate=CompressedFile/OriginalFile thus got the reversed graph, although the meaning is still the same. The lower the compression rate the greater the compressed file, thus higher entropy limits the how far a file can be compressed as on Figure 6. 
4. ConclusionJust as the second assignment the probability of 0s and 1s generated matched the theory. We use reversed equation for compression rate and the as expected the graph become backward thought it is the same thing that lower entropy allows greater compression. The difference in this assignment is that we used piecewise linear chaotic binary sequence which is more complex than skew tent map but allows various map design. This opens possibility to produce different kinds of sequences. 5. Source CodeThe source code again is written in Octave and Matlab type language. The script this time is manual so better edit the script and change the values of you want to use it. Next time I might consider uploading the program to available online. close all clear clc x = 0:.001:1; p1 = 0.9; p2 = 0.8; c = p2/(p1+p2); a = 1/(1-(p1+p2)); if p1+p2 < 1 %positive slope c1 = c-(c/a); c2 = c+((1-c)/a ); d1 = c1*(1-c); %(we chose negative slope) d2 = 1-((1-c2)*c); %(we chose negative slope) a1 = -c/(c1-d1); %slope a = y2 - y1 / x2 - x1 (we chose negative) a2 = a; %positive slope a3 = (c-1)/(d2-c2); % (we chose negative slope) i = 0; for i = 1:length(x) if x(i) >= 0 && x(i) < c1 t(i) = (a1*(x(i)-d1))+c; elseif x(i) >= c1 && x(i) < c2 t(i) = a2*(x(i)-c1); else t(i) = (a3*(x(i)-c2))+1; end end figure plot(x,x,x,t,0,c,c,0,d1,0,c1,0,c2,0,d2,0); grid on; %title('p1 = 0.1 and p2 = 0.8'); xlabel('x'); ylabel('t'); %legend('reference', 'plot', 'c', 'c', 'd1', 'c1', 'c2', 'd2'); ylim([0 1]); N = 1000000; X(1) = 0.3; for i = 1:N if X(i) >= 0 && X(i) < c1 X(i+1) = (a1*(X(i)-d1))+c; elseif X(i) >= c1 && X(i) < c2 X(i+1) = a2*(X(i)-c1); else X(i+1) = (a3*(X(i)-c2))+1; end end figure plot(0:length(X)-1,X); figure hist(X,x,length(x)); %title('p1=0.1 p2=0.8 N=1000000'); xlim([0 1]); ylim([0 2]); P0_theory = c; P1_theory = 1-c; P1l0_theory = p1; P0l1_theory = p2; P0l0_theory = 1-p1; P1l1_theory = 1-p2; P01_theory = P0l1_theory*P1_theory; P10_theory = P1l0_theory*P0_theory; P00_theory = P0l0_theory*P0_theory; P11_theory = P1l1_theory*P1_theory; H_theory = ((p2/(p1+p2))*((-p1*log2(p1))-((1-p1)*log2(1-p1)))) + ((p1/(p1+p2))*((-p2*log2(p2))-((1-p2)*log2(1-p2)))); fprintf('P(0) in theory is %f\n', P0_theory); fprintf('P(1) in theory is %f\n', P1_theory); fprintf('P(00) in theory is %f\n', P00_theory); fprintf('P(01) in theory is %f\n', P01_theory); fprintf('P(10) in theory is %f\n', P10_theory); fprintf('P(11) in theory is %f\n', P11_theory); fprintf('P(0|0) in theory is %f\n', P0l0_theory); fprintf('P(0|1) in theory is %f\n', P0l1_theory); fprintf('P(1|0) in theory is %f\n', P1l0_theory); fprintf('P(1|1) in theory is %f\n', P1l1_theory); fprintf('Entropy in theory is %f\n\n', H_theory); t = c; binary = X >= t; save("binary_sequence.dat", "binary"); P0_practical = P1_practical = P00_practical = P01_practical = P10_practical = P11_practical = 0; for i = 1:length(binary) if binary(i) == 0 P0_practical += 1; else P1_practical += 1; end if i == length(binary) break; end if binary(i) == 0 && binary(i+1) == 0 P00_practical += 1; elseif binary(i) == 0 && binary(i+1) == 1 P01_practical += 1; elseif binary(i) == 1 && binary(i+1) == 0 P10_practical += 1; else P11_practical += 1; end end P0l0_practical = ((P00_practical/length(binary))/(P0_practical/length(binary))); P0l1_practical = ((P01_practical/length(binary))/(P1_practical/length(binary))); P1l0_practical = ((P10_practical/length(binary))/(P0_practical/length(binary))); P1l1_practical = ((P11_practical/length(binary))/(P1_practical/length(binary))); H_pratical = ((P0l1_practical/(P1l0_practical+P0l1_practical))*((-P1l0_practical*log2(P1l0_practical))-((P0l0_practical)*log2(P0l0_practical)))) + ((P1l0_practical/(P1l0_practical+P0l1_practical))*((-P0l1_practical*log2(P0l1_practical))-((P1l1_practical)*log2(P1l1_practical)))); fprintf('The number of 0s = %d, P(0) in practice is %f\n', P0_practical, P0_practical/length(binary)); fprintf('The number of 1s = %d, P(1) in practice is %f\n', P1_practical, P1_practical/length(binary)); fprintf('The number of 00s = %d, P(00) in practice is %f\n', P00_practical, P00_practical/length(binary)); fprintf('The number of 01s = %d, P(01) in practice is %f\n', P01_practical, P01_practical/length(binary)); fprintf('The number of 10s = %d, P(10) in practice is %f\n', P10_practical, P10_practical/length(binary)); fprintf('The number of 11s = %d, P(11) in practice is %f\n', P11_practical, P11_practical/length(binary)); fprintf('P(0|0) in practice is %f\n', P0l0_practical); fprintf('P(0|1) in practice is %f\n', P0l1_practical); fprintf('P(1|0) in practice is %f\n', P1l0_practical); fprintf('P(1|1) in practice is %f\n', P1l1_practical); fprintf('Entropy in practice is %f\n\n', H_pratical); elseif p1+p2 > 1 % negative lope c1 = c-((c-1)/a); c2 = c-(c/a); d1 = c1*(1-c); % we chose negative slope d2 = 1-((1-c2)*(1-c)); % we chose positive slope a1 = -c/(c1-d1); %slope a = y2 - y1 / x2 - x1 (we chose negative) a2 = a; % negative lope a3 = c/(d2-c2); %(we chose negative) for i = 1:length(x) if x(i) >= 0 && x(i) < c1 t(i) = (a1*(x(i)-d1))+c; elseif x(i) >= c1 && x(i) < c2 t(i) =(a2*(x(i)-c1))+1; else t(i) = a3*(x(i)-c2); end end figure plot(x,x,x,t,0,c,c,0,d1,0,c1,0,c2,0,d2,0); grid on; %title('p1 = 0.9 and p2 = 0.8'); xlabel('x'); ylabel('t'); %legend('reference', 'plot', 'c', 'c', 'd1', 'c1', 'c2', 'd2'); ylim([0 1]); N = 1000000; X(1) = 0.3; for i = 1:N if X(i) >= 0 && X(i) < c1 X(i+1) = (a1*(X(i)-d1))+c; elseif X(i) >= c1 && X(i) < c2 X(i+1) =(a2*(X(i)-c1))+1; else X(i+1) = a3*(X(i)-c2); end end figure plot(0:length(X)-1,X); figure hist(X,x,length(x)); %title('p1=0.9 p2=0.8 N=1000000'); xlim([0 1]); ylim([0 2]); P0_theory = c; P1_theory = 1-c; P1l0_theory = p1; P0l1_theory = p2; P0l0_theory = 1-p1; P1l1_theory = 1-p2; P01_theory = P0l1_theory*P1_theory; P10_theory = P1l0_theory*P0_theory; P00_theory = P0l0_theory*P0_theory; P11_theory = P1l1_theory*P1_theory; H_theory = ((p2/(p1+p2))*((-p1*log2(p1))-((1-p1)*log2(1-p1)))) + ((p1/(p1+p2))*((-p2*log2(p2))-((1-p2)*log2(1-p2)))); fprintf('P(0) in theory is %f\n', P0_theory); fprintf('P(1) in theory is %f\n', P1_theory); fprintf('P(00) in theory is %f\n', P00_theory); fprintf('P(01) in theory is %f\n', P01_theory); fprintf('P(10) in theory is %f\n', P10_theory); fprintf('P(11) in theory is %f\n', P11_theory); fprintf('P(0|0) in theory is %f\n', P0l0_theory); fprintf('P(0|1) in theory is %f\n', P0l1_theory); fprintf('P(1|0) in theory is %f\n', P1l0_theory); fprintf('P(1|1) in theory is %f\n', P1l1_theory); fprintf('Entropy in theory is %f\n\n', H_theory); t = c; binary = X >= t; save("binary_sequence.dat", "binary"); P0_practical = P1_practical = P00_practical = P01_practical = P10_practical = P11_practical = 0; for i = 1:length(binary) if binary(i) == 0 P0_practical += 1; else P1_practical += 1; end if i == length(binary) break; end if binary(i) == 0 && binary(i+1) == 0 P00_practical += 1; elseif binary(i) == 0 && binary(i+1) == 1 P01_practical += 1; elseif binary(i) == 1 && binary(i+1) == 0 P10_practical += 1; else P11_practical += 1; end end P0l0_practical = ((P00_practical/length(binary))/(P0_practical/length(binary))); P0l1_practical = ((P01_practical/length(binary))/(P1_practical/length(binary))); P1l0_practical = ((P10_practical/length(binary))/(P0_practical/length(binary))); P1l1_practical = ((P11_practical/length(binary))/(P1_practical/length(binary))); H_pratical = ((P0l1_practical/(P1l0_practical+P0l1_practical))*((-P1l0_practical*log2(P1l0_practical))-((P0l0_practical)*log2(P0l0_practical)))) + ((P1l0_practical/(P1l0_practical+P0l1_practical))*((-P0l1_practical*log2(P0l1_practical))-((P1l1_practical)*log2(P1l1_practical)))); fprintf('The number of 0s = %d, P(0) in practice is %f\n', P0_practical, P0_practical/length(binary)); fprintf('The number of 1s = %d, P(1) in practice is %f\n', P1_practical, P1_practical/length(binary)); fprintf('The number of 00s = %d, P(00) in practice is %f\n', P00_practical, P00_practical/length(binary)); fprintf('The number of 01s = %d, P(01) in practice is %f\n', P01_practical, P01_practical/length(binary)); fprintf('The number of 10s = %d, P(10) in practice is %f\n', P10_practical, P10_practical/length(binary)); fprintf('The number of 11s = %d, P(11) in practice is %f\n', P11_practical, P11_practical/length(binary)); fprintf('P(0|0) in practice is %f\n', P0l0_practical); fprintf('P(0|1) in practice is %f\n', P0l1_practical); fprintf('P(1|0) in practice is %f\n', P1l0_practical); fprintf('P(1|1) in practice is %f\n', P1l1_practical); fprintf('Entropy in practice is %f\n\n', H_pratical); else fprintf('you cannot do this'); end 0. NoteThis is the second assignment from my Masters Applied Digital Information Theory Course which has never been published anywhere and I, as the author and copyright holder, license this assignment customized CC-BY-SA where anyone can share, copy, republish, and sell on condition to state my name as the author and notify that the original and open version available here. 1. IntroductionOn the previous assignment we generate a chaotic sequence based on skew tent maps, and this time we generate a binary sequence (either '0' or '1'). On this occasion we generate the chaotic binary sequence based on the threshold function. bin = 0 if (x < c) bin = 1 if (x ≥ c) When a sequence value 'x' is less than critical point 'c' the binary value will be '0' and when a sequence value 'x' is equal or greater to critical point 'c' the binary value will be '1'. For example the critical value is set as 'c' = 0.4 and chaotic sequence 'x' = [0.750000 0.416667 0.972222 0.046296 0.115741 0.289352 0.723380], the binary sequence will be 'bin' = [1 1 1 0 0 0 1] as Figure 1. 
2. Probability of binary sequenceUsing the chaotic sequence based on skew tent map to generate binary sequence we compute the probability the sequence value will be '0' or '1' as 'P(0) = c' and 'P(1) = 1-c'. Using the skew tent map we can compute 'P(00) = c x c', 'P(01) = c(1-c)', 'P(10) = (1-c)c', and 'P(11) = (1-c)(1-c)'. On Markov's chain the probability that '0' will remain '0' is 'P(0|0) = c', '0' will become '1' is 'P(1|0) = 1-c', and so-on 'P(0|1) = c', 'P(1|1) = 1-c'. We continue the assignment using the previous assignment to generate the binary sequence and calculate the probability of '0' and '1' theoretically and the actual number of '0' and '1' on the binary sequence generated. We used the initial value 'x(1) = 0.3' and trials of 'c = 0.1, 0.2, 0.301, 0.4, 0.6, 0.7, 0.8, 0.9'. The total sequence generated is 2000000 values (2 Millions). The result is on Table 1. Table 1. Result of theoritical calculation and actual
While the theoretical probability was calculated based on the formula, we count how much '0's and '1's in the sequence consist of 2 Millions binary values. For example using 'c = 0.4' we got 799594 '0's and 1200406 '1's in the 2 Millions sequence. So the actual probability of '0' is '799594/2000000 = 0.399797' and '1' is '1200406/2000000 = 0.600203'. For '00's is 319635, '01's is 479958, '10' is 479958, and '11' is 720449. Everything else is on Table 1, and actual data matched the theory. For Entropy and compression ratio is discussed on the next section. 3. Entropy vs Compression RatioOn this binary sequence we can calculate the entropy which is how much important information contained. The higher the entropy (more important information) the lower the compression ratio (the least it can be compressed). Based on Table 1 we also calculated entropy of the sequence with the following formula. Entropy = -P(1)log2P(1) - P(0)log2P(0) On this experiment the generated 2 million binary sequence is saved into a '.dat' file. The raw file for all 'c' value will equal to 2MB. Here we chose to compress the '.dat' file into '.tar.bz2' format which is a common compression method in Linux. Finally we can plot the entropy to the compression ratio on Figure 2 which is as stated in the theory that the compression value increases with lower entropy. 
4. When t ≠ c is not memoryless
When generating the binary sequence uses the threshold function bin = 0 (x < t) @ 1 ( x ≥ t), on above section it's automatically adjust that t = c to produce a memoryless binary sequence. One of the ways to show that the binary sequence is memoryless is that it fulfills Markov's chain on Figure 3, other than through the Bernoulli trials and independent and identically distributed (iid). We see that on table 2 that the probability is not balance, the probability of turning and remains '0' should be the same, same goes for the probability of turning to 1. Table 2. Data of t ≠ c
5. ConclusionUsing the chaotic sequence generated by skew tent map we can generate the random binary sequence with the probability of '0's and '1's computable. The result above shows that the theoretical probability of '0's, '1's, '00's, '01's, '10's, '11's, and the Markov's chain where the probability of '0' will remain '0', will turn to '1', '1' will remain '1', or turn to '0' matches from the actual binary sequence generated. The theory is true to the actual. On the second case where we compare the entropy to capability of the compression, the greater the entropy the less the compression ratio. We found that the sequence is not memoryless when t ≠ c because it does not fulfill the Markov's Chain. 6. Source CodeThe script is created in Ruby language, use Ruby to run. #!/usr/bin/ruby -w x = c = Array.new; binary_sequence = Array.new; $P0 = $P1 = $P00 = $P01 = $P10 = $P11 = $P0l0 = $P0l1 = $P1l0 = $P1l1 = 0; print "Input initial value x[1] from 0 ~ 1: "; x[1] = gets.chomp.to_f; print "\nInput critical point c[1] from 0 ~ 1: "; c = gets.chomp.to_f; print "\nInput number of sequence N: "; N = gets.chomp.to_f; for n in 1..N if x[n] >= 0 and x[n] < c x[n+1] = x[n]/c; elsif x[n] >= c and x[n] <= 1 x[n+1] = (1-x[n])/(1-c); else print "x must be from 0 ~ 1"; end end puts "P(0)_theory = c = #{c}"; puts "P(1)_theory = 1-c = #{1-c}"; puts "P(00)_theory = c*c = #{c*c}"; puts "P(01)_theory = c(1-c) = #{c*(1-c)}"; puts "P(10)_theory = (1-c)c = #{(1-c)*c}"; puts "P(11)_theory = (1-c)*(1-c) = #{(1-c)*(1-c)}"; puts "P(0|0)_theory = c = #{c}"; puts "P(0|1)_theory = c = #{c}"; puts "P(1|0)_theory = 1-c = #{1-c}"; puts "P(1|1)_theory = 1-c = #{1-c}"; puts ""; file = File.new("binary_sequence.dat", "w"); for n in 1..N if x[n] < c binary_sequence[n] = 0; $P0 += 1; elsif x[n] >= c binary_sequence[n] = 1; $P1 += 1; else print "something is wrong"; end #print binary_sequence[n]; file.syswrite(binary_sequence[n]); end P0_actual = $P0/N.to_f; P1_actual = $P1/N.to_f; for n in 1..N if binary_sequence[n] == 0 and binary_sequence[n+1] == 0 $P00 += 1; elsif binary_sequence[n] == 0 and binary_sequence[n+1] == 1 $P01 += 1; elsif binary_sequence[n] == 1 and binary_sequence[n+1] == 0 $P10 += 1; else $P11 += 1; end end P00_actual = $P00/N.to_f; P01_actual = $P01/N.to_f; P10_actual = $P10/N.to_f; P11_actual = $P11/N.to_f; P0l0_actual = P00_actual/P0_actual; P0l1_actual = P01_actual/P1_actual; P1l0_actual = P10_actual/P0_actual; P1l1_actual = P11_actual/P1_actual; puts "P(0)_actual = #{P0_actual}"; puts "P(1)_actual = #{P1_actual}"; puts "P(00)_actual = #{P00_actual}"; puts "P(01)_actual = #{P01_actual}"; puts "P(10)_actual = #{P10_actual}"; puts "P(11)_actual = #{P11_actual}"; puts "P(0|0)_actual = #{P0l0_actual}"; puts "P(0|1)_actual = #{P0l1_actual}"; puts "P(1|0)_actual = #{P1l0_actual}"; puts "P(1|1)_actual = #{P1l1_actual}"; puts ""; puts Entropy = ((-P1_actual)*(Math.log2(P1_actual)))-((P0_actual)*(Math.log2(P0_actual))); puts "Total of '0' is #{$P0}"; puts "Total of '1' is #{$P1}"; puts "Total of '00' is #{$P00}"; puts "Total of '01' is #{$P01}"; puts "Total of '10' is #{$P10}"; puts "Total of '11' is #{$P11}"; 0. NoteThis is the first assignment from my Masters Applied Digital Information Theory Course which has never been published anywhere and I, as the author and copyright holder, license this assignment customized CC-BY-SA where anyone can share, copy, republish, and sell on condition to state my name as the author and notify that the original and open version available here. 1. IntroductionThe chaos theory is a field of study in mathematics that studies the behaviour of dynamical system. Rober L. Devaney stated a system can be chaotic if it is sensitive to initial value, topologically mixing, and have a dense periodic orbit. The theory was summarized by Edward Lorenz. Although the system was highly determined by the initial value, in the end the sequence is unpredictable. Chaos exist in many natural system such as the climate and whether. In the field of computer science, it's applied to generate random values. 2. Tent MapThe tent map can be formulated as t = x/c for 0 ≤ x < c and t = (1-x)/(1-c) for c ≤ x ≤ 1 where: c = critical point x = initial value t = tent map (next value for sequence) For example c = 0.5 with x from 0 to 1: 
Figure 1 is based on the equation that the value would range from 0 to 1, and when “x” reached the critical point, the value of “t” will equals to 1. It is up to us to decide the critical point, as in Figure 2 shows if “c” equals to 0.2. Another information is if “x” equals to 0 or 1 the end result will be 0, thus using this value is not recommended. 
3. Chaotic SequenceIn some areas the tent map equation is used to generate chaotic sequence, here t(n) = x(n+1). The equation would turn into x(n+1) = (x(n))/c for 0 ≤ x(n) < c and x(n+1) = (1-x(n))/(1-c) for c ≤ x(n) ≤ 1. Why the equation is stated differently? So the value of x(n+1) will never exceed 1. For example if “c = 0.4” and “x = 0.5” and use the first equation “x(n)/c = 0.5/0.4 = 1.25”. That won't do so we use “1-x(n)/1-c = 1 - 0.5 / 1 - 0.4 = 0.5/0.6 = 0.833”. Another example “c = 0.7” and “x = 0.4” which we can't use the second equation “1-x(n)/1-c = 1 - 0.4 / 1 - 0.7 = 0.6/0.3 = 2” but we use “x(n)/c = 0.7/0.4 = 0.571”. As stated in the chaos theory the next sequence “x(n+1)” is highly dependable on the initial value “x(n)” (x(2) depends on x(1), x(3) depends on x(2), etc), as we plot the sequences it will looked unpredictable. 3.1 For “x” equals to 0 and 1, and “c” equals to 0.5

Figure 3 is only plotted to the 10th “n” because the result is obvious. For x(1) (initial) equals to 0, x(2) = 0/c = 0 and for x(1) x(2) = (1-1)/(1-c) = 0/(1-c) = 0. Once the value is zero, the next value will always be zero, and for x(1) equals to c x(2) = c/c = 1, x(3) = (1-1)/(1-c) = 0. When “x” reaches critical point “c” it will result to 1, and once the next value “x(n+1)” equals to 1 the next value “x(n+2)” will result to 0, and once it reaches to 0 the next value will always be 0. With the explanation above we can see that it's not recommended to use a critical point “c” equals to 0.5. In Figure 4b when “c = 0.5” it's susceptible for “x” in reaching “c”. On the 54th “n” “x(n) = c” and “x(n+1) = 1”, then the next result will always be 0. 

3.2 For “c” equals to 0.6 and x = 0.3 and 0.8Figure 5a shows that when “c” equals to 0.6, “t” will have the same value when “x” equals to 0.3 and 0.8. Thus the sequence generated at Figure 5b will be the same. At the same time it is shown the sequence will be continuous. 

3.3 Sensitivity to Initial ValueThe chaos theory stated that it is sensitive to initial value, just a slight change can totally change the whole sequence. For example “c = 0.4” and we'll try “x” with initial value of 0.7, 0.71, 0.72, 0.73 on Figure 6 and “x” with initial value of 0.7111, 0.71111, 0.711111, 0.7111111 on Figure 7. 



On Figure 7 we tried even more extreme which we plot of each initial value with a difference of 0.0001, 0.00001, 0.000001, and 0.0000001. There seems to be no difference on up to the 10th sequence, but the sequences finally deviated on the 15th “n” sequence for 0.7111 and 0.71111, then followed up by the other initial values that have smaller difference. 



Even with small difference it's still unpredictable on the 100th sequence, let alone the 1000th sequence. This proofs the sensitivity to initial values (where the “x” starts). 3.4 Distributions of the sequencesOn this section we will see the distribution of value from 0 to 1, specifically from 0, 0.01, 0.02 ~ 1. Only 0 to 1 because the sequence is formulated to not go below 0 and go above 1. The histogram on Figure 8 shows the distribution of value with critical point “c” of 0.4 and initial value “x(1)” of 0.7. This time we produce a sequence as much as “n = 1000000” (million) (the more the sequence the better). Plotting that much data cannot be seen in one graph, in other word it's not visible, but with histogram we can see what and how much the values contained in the sequence. 
Figure 8 shows that there is around 10000 data with a value of 0.1, 0.2, and so on. The hist() function works by rounding, for example the value of 0.1111 will be rounded to 0.1, and the value of 0.15 rounded to 0.2. Then the value is counted up (how many 0.1s there is) and a distrubution histogram was graphed. Finally it can be said that the distribution of data is uniformed since the amount of data for each value is almost the same. 4. ConclusionWe can conclude that the chaos sequence is formed by previous value like a memory system. Since it's very sensitive to initial value, the further the sequence becomes more unpredictable. The theory is a simple application of the natural system for example the weather. We can predict the weather maybe for a month, beyond that it's likely miss prediction. The course of whether is determined by its starting point, the wrong initial value will lead to the wrong prediction. On the other hand the more accurate the initial value and the formula, the longer the validity of the prediction. Since the unpredictable outcome of this chaos theory, in computer it can be also applied for creating random values. On this simulation the distribution of the skew tent to the chaotic sequence, we found it to be uniformed. 5. Source CodeThe source code is written in “m file” that could run on Matlab or Octave alike. It is a function which can be run as “stcsfp(xo,c,N)” where “xo = initial value”, “c = critical point”, and “N = number of sequence”. For example the plotted graph above we run by “stcsfp(0.7,0.4,1000000)”, but we can delete function if it seems inconvenient by deleting the 1st line and use it as regular script. The graphs above are done by few modifications of the code, but here on Code 1 resides the pure source code.
function t = stcsfp(xo,c,N)
% === TENT MAP === %
X = 0:.1:1;
for n = 1:11
if X(n) >= 0 && X(n) < c
T(n) = X(n)/c;
elseif X(n) >= c && X(n) <=1
T(n) = (1-X(n))/(1-c);
else
printf("x initial must be from 0 to 1");
end
end
% === MAIN CALCULATION === %
x(1) = xo;
for n = 1:N
if x(n) >= 0 && x(n) < c
t(n) = x(n)/c;
x(n+1) = t(n);
elseif x(n) >= c && x(n) <=1
t(n) = (1-x(n))/(1-c);
x(n+1) = t(n);
else
printf("x initial must be from 0 to 1");
end
end
%Plot Tent Map%
figure
plot(X, T, xo, t(1));
title("Tent Map");
xlabel("X");
ylabel("T");
%legend("fill this in")
%Plot Sequence%
figure
plot(t);
title("Sequence Generated");
xlabel("n");
ylabel("t(n) or x(n+1)");
ylim([-0.1 1.1]);
%legend(["fill this in"]);
%xlim([1 20])
%Plot Histogram%
figure
hist(t, 0:.01:1);
title("Distribution");
xlabel("Value");
ylabel("Count");
xlim([-0.1 1.1]);
Code 1. Skew Tent Chaotic Sequence Program Mirrors
Mendukung Media Sosial Kripto Torum Seperti Duta Besar dengan Menanggapi Posting Terkait Lainnya23/1/2021 
Mencari dan Menanggapi Posting Terkait Torum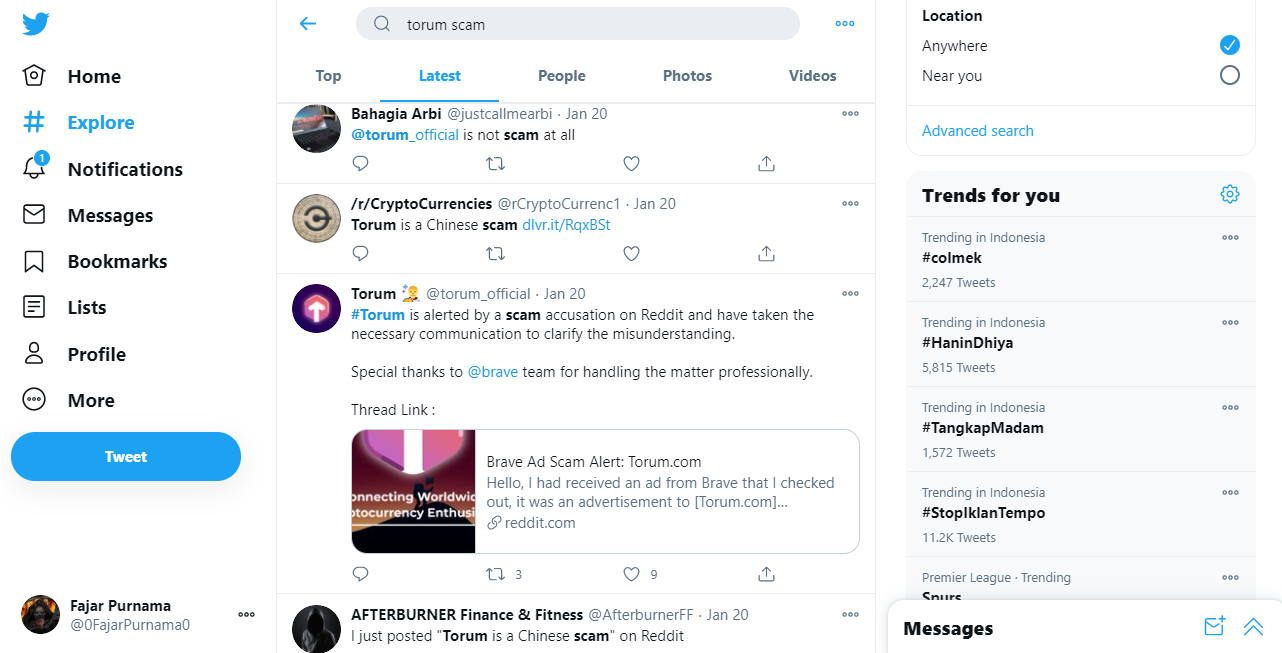
Menjadi Pendukung hingga PejuangKebalikan dari pembenci di mana Anda membela apa pun yang terjadi dan mengekspresikan perasaan Anda hanya karena Anda mendukung Torum:
Selain bertahan, Anda dapat menyerang lawan:
Menjadi Pihak ke-3 yang ObyektifSaya melihat banyak pendukung memberikan pernyataan sederhana seperti yang saya tunjukkan sebelumnya tetapi secara pribadi saya tidak merekomendasinya karena tidak peduli seberapa banyak Anda mendukung, Anda bukanlah pendiri atau pemilik, Anda adalah Anda. Alasan lainnya adalah fakta dan kebenaran selalu menang dalam jangka panjang. Tidak seperti menjadi suporter, Anda harus bertindak seperti robot tanpa emosi dan berbicara hanya berdasarkan salah satu atau semua tentang data, logika, pendapat Anda sendiri, dll.
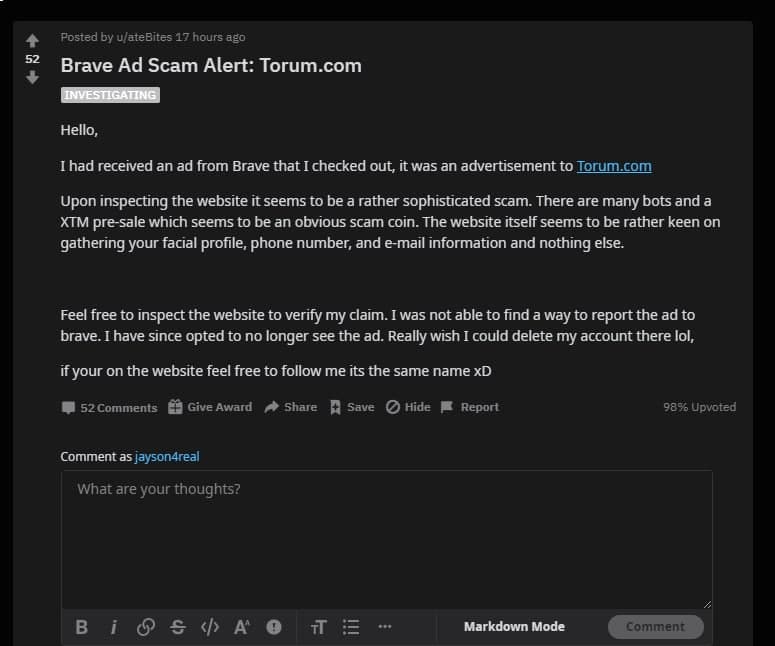
Menjadi Penjahat ke-3Meskipun orang tidak percaya setiap saat ketika saya mengakui bahwa saya memiliki temperamen buruk tetapi mereka tidak mengeluh ketika saya mengakui bahwa saya sarkastik dan saya meminta maaf. Ini berbeda dengan menjadi pendukung yang menyerang atau pihak ketiga yang objektif yang mengkritik tetapi lebih seperti area abu-abu di mana Anda ingin menunjukkan taring Anda pada penuduh atau menunjukkan taring Anda kepada kedua belah pihak hanya untuk diri Anda sendiri. Berikut adalah utas lain: Torum is a Chinese scam from r/torumtech Saya tidak akan menyangkal jika komentar saya dituduh mencari perhatian tetapi secara pribadi saya hanya ingin mengungkapkan perasaan saya:
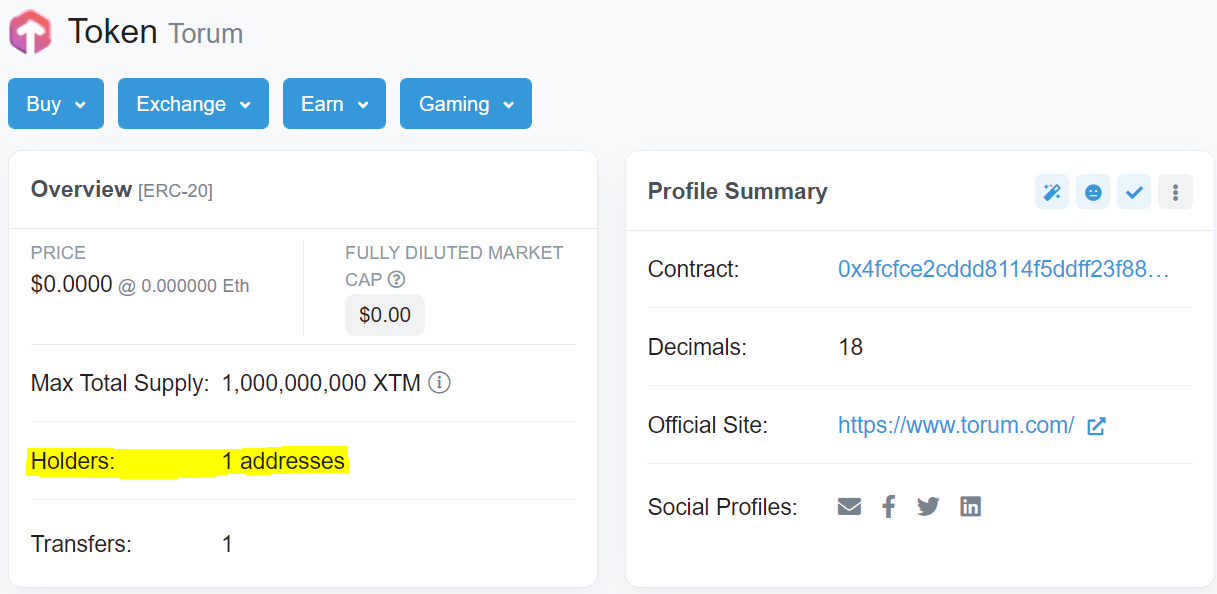
Menjadi Seorang PelaporNB, Saya minta maaf kepada penuduh yang membaca komentar kasar di atas. Ini hanyalah contoh bagaimana orang dapat mendekati dan saya tahu bahwa Anda telah menyelesaikan masalah Anda di antara mereka ketika saya membaca komentar terakhir Anda dan sebaliknya komentar saya untuk utas Anda ada di bawah: CardIni adalah peran favorit saya karena saya suka membimbing orang dan membiarkan mereka berpikir sendiri. Di sini Anda tidak menyerang atau membela atau melibatkan emosi apa pun. Anda hanya memberikan informasi dan tidak lebih dari itu. Misalnya, di bawah ini komentar saya tentang tuduhan scam:
Duta Besar Mana Yang Ditugasi Untuk Pekerjaan Ini?
|
Archives
August 2022
Categories
All
source code
old source code Get any amount of 0FP0EXP tokens to stop automatic JavaScript Mining or get 10 0FP0EXP tokens to remove this completely. get 30 0FP0EXP Token to remove this paypal donation. get 20 0FP0EXP Token to remove my personal ADS. Get 50 0FP0EXP Token to remove my NFTS advertisements! |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 RSS Feed
RSS Feed

